- kubernetes 中的删除策略
- GarbageCollectorController 源码分析
- 示例
- 总结
在前面几篇关于 controller 源码分析的文章中多次提到了当删除一个对象时,其对应的 controller 并不会执行删除对象的操作,在 kubernetes 中对象的回收操作是由 GarbageCollectorController 负责的,其作用就是当删除一个对象时,会根据指定的删除策略回收该对象及其依赖对象,本文会深入分析垃圾收集背后的实现。
kubernetes 中的删除策略
kubernetes 中有三种删除策略:Orphan、Foreground 和 Background,三种删除策略的意义分别为:
Orphan策略:非级联删除,删除对象时,不会自动删除它的依赖或者是子对象,这些依赖被称作是原对象的孤儿对象,例如当执行以下命令时会使用Orphan策略进行删除,此时 ds 的依赖对象controllerrevision不会被删除;
$ kubectl delete ds/nginx-ds --cascade=false
Background策略:在该模式下,kubernetes 会立即删除该对象,然后垃圾收集器会在后台删除这些该对象的依赖对象;Foreground策略:在该模式下,对象首先进入“删除中”状态,即会设置对象的deletionTimestamp字段并且对象的metadata.finalizers字段包含了值 “foregroundDeletion”,此时该对象依然存在,然后垃圾收集器会删除该对象的所有依赖对象,垃圾收集器在删除了所有“Blocking” 状态的依赖对象(指其子对象中ownerReference.blockOwnerDeletion=true的对象)之后,然后才会删除对象本身;
在 v1.9 以前的版本中,大部分 controller 默认的删除策略为 Orphan,从 v1.9 开始,对于 apps/v1 下的资源默认使用 Background 模式。以上三种删除策略都可以在删除对象时通过设置 deleteOptions.propagationPolicy 字段进行指定,如下所示:
$ curl -k -v -XDELETE -H "Accept: application/json" -H "Content-Type: application/json" -d '{"propagationPolicy":"Foreground"}' 'https://192.168.99.108:8443/apis/apps/v1/namespaces/default/daemonsets/nginx-ds'
finalizer 机制
finalizer 是在删除对象时设置的一个 hook,其目的是为了让对象在删除前确认其子对象已经被完全删除,k8s 中默认有两种 finalizer:OrphanFinalizer 和 ForegroundFinalizer,finalizer 存在于对象的 ObjectMeta 中,当一个对象的依赖对象被删除后其对应的 finalizers 字段也会被移除,只有 finalizers 字段为空时,apiserver 才会删除该对象。
{
......
"metadata": {
......
"finalizers": [
"foregroundDeletion"
]
}
......
}
此外,finalizer 不仅仅支持以上两种字段,在使用自定义 controller 时也可以在 CR 中设置自定义的 finalizer 标识。
GarbageCollectorController 源码分析
kubernetes 版本:v1.16
GarbageCollectorController 负责回收 kubernetes 中的资源,要回收 kubernetes 中所有资源首先得监控所有资源,GarbageCollectorController 会监听集群中所有可删除资源产生的所有事件,这些事件会被放入到一个队列中,然后 controller 会启动多个 goroutine 处理队列中的事件,若为删除事件会根据对象的删除策略删除关联的对象,对于非删除事件会更新对象之间的依赖关系。
startGarbageCollectorController
首先还是看 GarbageCollectorController 的启动方法 startGarbageCollectorController,其主要逻辑为:
- 1、初始化 discoveryClient,discoveryClient 主要用来获取集群中的所有资源;
- 2、调用
garbagecollector.GetDeletableResources获取集群内所有可删除的资源对象,支持 "delete", "list", "watch" 三种操作的 resource 称为deletableResource; - 3、调用
garbagecollector.NewGarbageCollector初始化 garbageCollector 对象; - 4、调用
garbageCollector.Run启动 garbageCollector; - 5、调用
garbageCollector.Sync监听集群中的DeletableResources,当出现新的DeletableResources时同步到 monitors 中,确保监控集群中的所有资源; - 6、调用
garbagecollector.NewDebugHandler注册 debug 接口,用来提供集群内所有对象的关联关系;
k8s.io/kubernetes/cmd/kube-controller-manager/app/core.go:443
func startGarbageCollectorController(ctx ControllerContext) (http.Handler, bool, error) {
if !ctx.ComponentConfig.GarbageCollectorController.EnableGarbageCollector {
return nil, false, nil
}
// 1、初始化 discoveryClient
gcClientset := ctx.ClientBuilder.ClientOrDie("generic-garbage-collector")
discoveryClient := cacheddiscovery.NewMemCacheClient(gcClientset.Discovery())
config := ctx.ClientBuilder.ConfigOrDie("generic-garbage-collector")
metadataClient, err := metadata.NewForConfig(config)
if err != nil {
return nil, true, err
}
// 2、获取 deletableResource
deletableResources := garbagecollector.GetDeletableResources(discoveryClient)
ignoredResources := make(map[schema.GroupResource]struct{})
for _, r := range ctx.ComponentConfig.GarbageCollectorController.GCIgnoredResources {
ignoredResources[schema.GroupResource{Group: r.Group, Resource: r.Resource}] = struct{}{}
}
// 3、初始化 garbageCollector 对象
garbageCollector, err := garbagecollector.NewGarbageCollector(
......
)
if err != nil {
return nil, true, fmt.Errorf("failed to start the generic garbage collector: %v", err)
}
// 4、启动 garbage collector
workers := int(ctx.ComponentConfig.GarbageCollectorController.ConcurrentGCSyncs)
go garbageCollector.Run(workers, ctx.Stop)
// 5、监听集群中的 DeletableResources
go garbageCollector.Sync(gcClientset.Discovery(), 30*time.Second, ctx.Stop)
// 6、注册 debug 接口
return garbagecollector.NewDebugHandler(garbageCollector), true, nil
}
在 startGarbageCollectorController 中主要调用了四种方法garbagecollector.NewGarbageCollector、garbageCollector.Run、garbageCollector.Sync 和 garbagecollector.NewDebugHandler 来完成核心功能,下面主要针对这四种方法进行说明。
garbagecollector.NewGarbageCollector
NewGarbageCollector 的主要功能是初始化 GarbageCollector 和 GraphBuilder 对象,并调用 gb.syncMonitors方法初始化 deletableResources 中所有 resource controller 的 informer。GarbageCollector 的主要作用是启动 GraphBuilder 以及启动所有的消费者,GraphBuilder 的主要作用是启动所有的生产者。
k8s.io/kubernetes/pkg/controller/garbagecollector/garbagecollector.go:74
func NewGarbageCollector(......) (*GarbageCollector, error) {
......
gc := &GarbageCollector{
......
}
gb := &GraphBuilder{
......
}
if err := gb.syncMonitors(deletableResources); err != nil {
utilruntime.HandleError(fmt.Errorf("failed to sync all monitors: %v", err))
}
gc.dependencyGraphBuilder = gb
return gc, nil
}
gb.syncMonitors
syncMonitors 的主要作用是初始化各个资源对象的 informer,并调用 gb.controllerFor 为每种资源注册 eventHandler,此处每种资源被称为 monitors,因为为每种资源注册 eventHandler 时,对于 AddFunc、UpdateFunc 和 DeleteFunc 都会将对应的 event push 到 graphChanges 队列中,每种资源对象的 informer 都作为生产者。
k8s.io/kubernetes/pkg/controller/garbagecollector/graph_builder.go:179
func (gb *GraphBuilder) syncMonitors(resources map[schema.GroupVersionResource]struct{}) error {
gb.monitorLock.Lock()
defer gb.monitorLock.Unlock()
......
for resource := range resources {
if _, ok := gb.ignoredResources[resource.GroupResource()]; ok {
continue
}
......
kind, err := gb.restMapper.KindFor(resource)
if err != nil {
errs = append(errs, fmt.Errorf("couldn't look up resource %q: %v", resource, err))
continue
}
// 为 resource 的 controller 注册 eventHandler
c, s, err := gb.controllerFor(resource, kind)
if err != nil {
errs = append(errs, fmt.Errorf("couldn't start monitor for resource %q: %v", resource, err))
continue
}
current[resource] = &monitor{store: s, controller: c}
added++
}
gb.monitors = current
for _, monitor := range toRemove {
if monitor.stopCh != nil {
close(monitor.stopCh)
}
}
return utilerrors.NewAggregate(errs)
}
gb.controllerFor
在 gb.controllerFor中主要是为每个 deletableResources 的 informer 注册 eventHandler,此处就可以看到真正的生产者了。
k8s.io/kubernetes/pkg/controller/garbagecollector/graph_builder.go:127
func (gb *GraphBuilder) controllerFor(resource schema.GroupVersionResource, kind schema.GroupVersionKind) (cache.Controller, cache.Store, error) {
handlers := cache.ResourceEventHandlerFuncs{
AddFunc: func(obj interface{}) {
event := &event{
eventType: addEvent,
obj: obj,
gvk: kind,
}
// 将对应的 event push 到 graphChanges 队列中
gb.graphChanges.Add(event)
},
UpdateFunc: func(oldObj, newObj interface{}) {
event := &event{
eventType: updateEvent,
obj: newObj,
oldObj: oldObj,
gvk: kind,
}
// 将对应的 event push 到 graphChanges 队列中
gb.graphChanges.Add(event)
},
DeleteFunc: func(obj interface{}) {
if deletedFinalStateUnknown, ok := obj.(cache.DeletedFinalStateUnknown); ok {
obj = deletedFinalStateUnknown.Obj
}
event := &event{
eventType: deleteEvent,
obj: obj,
gvk: kind,
}
// 将对应的 event push 到 graphChanges 队列中
gb.graphChanges.Add(event)
},
}
shared, err := gb.sharedInformers.ForResource(resource)
if err != nil {
return nil, nil, err
}
shared.Informer().AddEventHandlerWithResyncPeriod(handlers, ResourceResyncTime)
return shared.Informer().GetController(), shared.Informer().GetStore(), nil
}
至此 NewGarbageCollector 的功能已经分析完了,在 NewGarbageCollector 中初始化了两个对象 GarbageCollector 和 GraphBuilder,然后在 gb.syncMonitors 中初始化了所有 deletableResources 的 informer,为每个 informer 添加 eventHandler 并将监听到的所有 event push 到 graphChanges 队列中,此处每个 informer 都被称为 monitor,所有 informer 都被称为生产者。graphChanges 是 GraphBuilder 中的一个对象,GraphBuilder 的主要功能是作为一个生产者,其会处理 graphChanges 中的所有事件并进行分类,将事件放入到 attemptToDelete 和 attemptToOrphan 两个队列中,具体处理逻辑下文讲述。
NewGarbageCollector 中的调用逻辑如下所示:
|--> ctx.ClientBuilder.
| ClientOrDie
|
|
|--> cacheddiscovery.
| NewMemCacheClient
| |--> gb.sharedInformers.
| | ForResource
| |
startGarbage ----|--> garbagecollector. --> gb.syncMonitors --> gb.controllerFor --|
CollectorController | NewGarbageCollector |
| |
| |--> shared.Informer().
| AddEventHandlerWithResyncPeriod
|--> garbageCollector.Run
|
|
|--> garbageCollector.Sync
|
|
|--> garbagecollector.NewDebugHandler
garbageCollector.Run
上文已经详述了 NewGarbageCollector 的主要功能,然后继续分析 startGarbageCollectorController 中的第二个核心方法 garbageCollector.Run,garbageCollector.Run 的主要作用是启动所有的生产者和消费者,其首先会调用 gc.dependencyGraphBuilder.Run 启动所有的生产者,即 monitors,然后再启动一个 goroutine 处理 graphChanges 队列中的事件并分别放到 attemptToDelete 和 attemptToOrphan 两个队列中,dependencyGraphBuilder 即上文提到的 GraphBuilder,run 方法会调用 gc.runAttemptToDeleteWorker 和 gc.runAttemptToOrphanWorker 启动多个 goroutine 处理 attemptToDelete 和 attemptToOrphan 两个队列中的事件。
k8s.io/kubernetes/pkg/controller/garbagecollector/garbagecollector.go:124
func (gc *GarbageCollector) Run(workers int, stopCh <-chan struct{}) {
defer utilruntime.HandleCrash()
defer gc.attemptToDelete.ShutDown()
defer gc.attemptToOrphan.ShutDown()
defer gc.dependencyGraphBuilder.graphChanges.ShutDown()
defer klog.Infof("Shutting down garbage collector controller")
// 1、调用 gc.dependencyGraphBuilder.Run 启动所有的 monitors 即 informers,并且启动一个 goroutine 处理 graphChanges 中的事件将其分别放到 GraphBuilder 的 attemptToDelete 和 attemptToOrphan 两个 队列中;
go gc.dependencyGraphBuilder.Run(stopCh)
// 2、等待 informers 的 cache 同步完成
if !cache.WaitForNamedCacheSync("garbage collector", stopCh, gc.dependencyGraphBuilder.IsSynced) {
return
}
for i := 0; i < workers; i++ {
// 3、启动多个 goroutine 调用 gc.runAttemptToDeleteWorker 处理 attemptToDelete 中的事件
go wait.Until(gc.runAttemptToDeleteWorker, 1*time.Second, stopCh)
// 4、启动多个 goroutine 调用 gc.runAttemptToOrphanWorker 处理 attemptToDelete 中的事件
go wait.Until(gc.runAttemptToOrphanWorker, 1*time.Second, stopCh)
}
<-stopCh
}
Run 方法中调用了 gc.dependencyGraphBuilder.Run 来完成 GraphBuilder 的启动。
gc.dependencyGraphBuilder.Run
GraphBuilder 在 garbageCollector 整个环节中起到承上启下的作用,首先看一下 GraphBuilder 对象的结构:
type GraphBuilder struct {
restMapper meta.RESTMapper
// informers
monitors monitors
monitorLock sync.RWMutex
// 当 kube-controller-manager 中所有的 controllers 都启动后,informersStarted 会被 close 掉
// informersStarted 会被 close 掉的调用程序在 kube-controller-manager 的启动流程中
informersStarted <-chan struct{}
stopCh <-chan struct{}
// 当调用 GraphBuilder 的 run 方法时,running 会被设置为 true
running bool
metadataClient metadata.Interface
// informers 监听到的事件会放在 graphChanges 中
graphChanges workqueue.RateLimitingInterface
// 维护所有对象的依赖关系
uidToNode *concurrentUIDToNode
// GarbageCollector 作为消费者要处理 attemptToDelete 和 attemptToOrphan 两个队列中的事件
attemptToDelete workqueue.RateLimitingInterface
attemptToOrphan workqueue.RateLimitingInterface
absentOwnerCache *UIDCache
sharedInformers controller.InformerFactory
// 不需要被 gc 的资源
ignoredResources map[schema.GroupResource]struct{}
}
uidToNode
此处有必要先说明一下 uidToNode 的功能,uidToNode 数据结构中维护着所有对象的依赖关系,此处的依赖关系是指比如当创建一个 deployment 时会创建对应的 rs 以及 pod,pod 的 owner 就是 rs,rs 的 owner 是 deployment,rs 的 dependents 是其关联的所有 pod,deployment 的 dependents 是其关联的所有 rs。
uidToNode 中的 node 不是指 k8s 中的 node 节点,而是将 graphChanges 中的 event 转换为 node 对象,k8s 中所有 object 之间的级联关系是通过 node 的概念来维护的,garbageCollector 在后续的处理中会直接使用 node 对象,node 对象定义如下:
type concurrentUIDToNode struct {
uidToNodeLock sync.RWMutex
uidToNode map[types.UID]*node
}
type node struct {
identity objectReference
dependentsLock sync.RWMutex
// 其依赖项指 metadata.ownerReference 中的对象
dependents map[*node]struct{}
deletingDependents bool
deletingDependentsLock sync.RWMutex
beingDeleted bool
beingDeletedLock sync.RWMutex
// 当 virtual 值为 true 时,此时不确定该对象是否存在于 apiserver 中
virtual bool
virtualLock sync.RWMutex
// 对象本身的 OwnerReference 列表
owners []metav1.OwnerReference
}
GraphBuilder 主要有三个功能:
- 1、监控集群中所有的可删除资源;
- 2、基于 informers 中的资源在 uidToNode 数据结构中维护着所有对象的依赖关系;
- 3、处理 graphChanges 中的事件并放到 attemptToDelete 和 attemptToOrphan 两个队列中;
上文已经说了 gc.dependencyGraphBuilder.Run 的功能,启动所有的 informers 然后再启动一个 goroutine 处理 graphChanges 队列中的事件并分别放到 attemptToDelete 和 attemptToOrphan 两个队列中,代码如下所示:
k8s.io/kubernetes/pkg/controller/garbagecollector/graph_builder.go:281
func (gb *GraphBuilder) Run(stopCh <-chan struct{}) {
klog.Infof("GraphBuilder running")
defer klog.Infof("GraphBuilder stopping")
gb.monitorLock.Lock()
gb.stopCh = stopCh
gb.running = true
gb.monitorLock.Unlock()
gb.startMonitors()
// 调用 gb.runProcessGraphChanges
// 此处为死循环,除非收到 stopCh 信号,否则下面的代码不会被执行到
wait.Until(gb.runProcessGraphChanges, 1*time.Second, stopCh)
// 若执行到此处说明收到了 stopCh 的信号,此时需要停止所有的 running monitors
gb.monitorLock.Lock()
defer gb.monitorLock.Unlock()
monitors := gb.monitors
stopped := 0
for _, monitor := range monitors {
if monitor.stopCh != nil {
stopped++
close(monitor.stopCh)
}
}
gb.monitors = nil
}
gc.dependencyGraphBuilder.Run的核心是调用了 gb.startMonitors 和 gb.runProcessGraphChanges 两个方法来完成主要功能,继续看这两个方法的主要逻辑。
gb.startMonitors
startMonitors 的功能很简单就是启动所有的 informers,代码如下所示:
k8s.io/kubernetes/pkg/controller/garbagecollector/graph_builder.go:232
func (gb *GraphBuilder) startMonitors() {
gb.monitorLock.Lock()
defer gb.monitorLock.Unlock()
// 1、当 GraphBuilder 调用 run 方法后,running 会设置为 true
if !gb.running {
return
}
// 2、当 kube-controller-manager 中所有的 controllers 在启动流程中都启动后
// 会 close 掉 informersStarted
<-gb.informersStarted
// 3、启动所有 informer
monitors := gb.monitors
started := 0
for _, monitor := range monitors {
if monitor.stopCh == nil {
monitor.stopCh = make(chan struct{})
gb.sharedInformers.Start(gb.stopCh)
go monitor.Run()
started++
}
}
}
gb.runProcessGraphChanges
runProcessGraphChanges 方法的主要功能是处理 graphChanges 中的事件将其分别放到 GraphBuilder 的 attemptToDelete 和 attemptToOrphan 两个队列中,代码主要逻辑为:
- 1、从 graphChanges 队列中取出一个 item 即 event;
- 2、获取 event 的 accessor,accessor 是一个 object 的 meta.Interface,里面包含访问 object meta 中所有字段的方法;
- 3、通过 accessor 获取 UID 判断 uidToNode 中是否存在该 object;
- 4、若 uidToNode 中不存在该 node 且该事件是 addEvent 或 updateEvent,则为该 object 创建对应的 node,并调用
gb.insertNode将该 node 加到 uidToNode 中,然后将该 node 添加到其 owner 的 dependents 中,执行完gb.insertNode中的操作后再调用gb.processTransitions方法判断该对象是否处于删除状态,若处于删除状态会判断该对象是以orphan模式删除还是以foreground模式删除,若以orphan模式删除,则将该 node 加入到 attemptToOrphan 队列中,若以foreground模式删除则将该对象以及其所有 dependents 都加入到 attemptToDelete 队列中; 5、若 uidToNode 中存在该 node 且该事件是 addEvent 或 updateEvent 时,此时可能是一个 update 操作,调用
referencesDiffs方法检查该对象的OwnerReferences字段是否有变化,若有变化(1)调用gb.addUnblockedOwnersToDeleteQueue将被删除以及更新的 owner 对应的 node 加入到 attemptToDelete 中,因为此时该 node 中已被删除或更新的 owner 可能处于删除状态且阻塞在该 node 处,此时有三种方式避免该 node 的 owner 处于删除阻塞状态,一是等待该 node 被删除,二是将该 node 自身对应 owner 的OwnerReferences字段删除,三是将该 nodeOwnerReferences字段中对应 owner 的BlockOwnerDeletion设置为 false;(2)更新该 node 的 owners 列表;(3)若有新增的 owner,将该 node 加入到新 owner 的 dependents 中;(4) 若有被删除的 owner,将该 node 从已删除 owner 的 dependents 中删除;以上操作完成后,检查该 node 是否处于删除状态并进行标记,最后调用gb.processTransitions方法检查该 node 是否要被删除;举个例子,若以
foreground模式删除 deployment 时,deployment 的 dependents 列表中有对应的 rs,那么 deployment 的删除会阻塞住等待其依赖 rs 的删除,此时 rs 有三种方法不阻塞 deployment 的删除操作,一是 rs 对象被删除,二是删除 rs 对象OwnerReferences字段中对应的 deployment,三是将 rs 对象OwnerReferences字段中对应的 deployment 配置BlockOwnerDeletion设置为 false,文末会有示例演示该操作。6、若该事件为 deleteEvent,首先从 uidToNode 中删除该对象,然后从该 node 所有 owners 的 dependents 中删除该对象,将该 node 所有的 dependents 加入到 attemptToDelete 队列中,最后检查该 node 的所有 owners,若有处于删除状态的 owner,此时该 owner 可能处于删除阻塞状态正在等待该 node 的删除,将该 owner 加入到 attemptToDelete 中;
总结一下,当从 graphChanges 中取出 event 时,不管是什么 event,主要完成三件时,首先都会将 event 转化为 uidToNode 中的 node 对象,其次一是更新 uidToNode 中维护的依赖关系,二是更新该 node 的 owners 以及 owners 的 dependents,三是检查该 node 的 owners 是否要被删除以及该 node 的 dependents 是否要被删除,若需要删除则根据 node 的删除策略将其添加到 attemptToOrphan 或者 attemptToDelete 队列中;
k8s.io/kubernetes/pkg/controller/garbagecollector/graph_builder.go:526
func (gb *GraphBuilder) runProcessGraphChanges() {
for gb.processGraphChanges() {
}
}
func (gb *GraphBuilder) processGraphChanges() bool {
// 1、从 graphChanges 取出一个 event
item, quit := gb.graphChanges.Get()
if quit {
return false
}
defer gb.graphChanges.Done(item)
event, ok := item.(*event)
if !ok {
utilruntime.HandleError(fmt.Errorf("expect a *event, got %v", item))
return true
}
obj := event.obj
accessor, err := meta.Accessor(obj)
if err != nil {
utilruntime.HandleError(fmt.Errorf("cannot access obj: %v", err))
return true
}
// 2、若存在 node 对象,从 uidToNode 中取出该 event 的 node 对象
existingNode, found := gb.uidToNode.Read(accessor.GetUID())
if found {
existingNode.markObserved()
}
switch {
// 3、若 event 为 add 或 update 类型以及对应的 node 对象不存在时
case (event.eventType == addEvent || event.eventType == updateEvent) && !found:
// 4、为 node 创建 event 对象
newNode := &node{
......
}
// 5、在 uidToNode 中添加该 node 对象
gb.insertNode(newNode)
// 6、检查并处理 node 的删除操作
gb.processTransitions(event.oldObj, accessor, newNode)
// 7、若 event 为 add 或 update 类型以及对应的 node 对象存在时
case (event.eventType == addEvent || event.eventType == updateEvent) && found:
added, removed, changed := referencesDiffs(existingNode.owners, accessor.GetOwnerReferences())
// 8、若 node 的 owners 有变化
if len(added) != 0 || len(removed) != 0 || len(changed) != 0 {
gb.addUnblockedOwnersToDeleteQueue(removed, changed)
// 9、更新 uidToNode 中的 owners
existingNode.owners = accessor.GetOwnerReferences()
// 10、添加更新后 Owners 对应的 dependent
gb.addDependentToOwners(existingNode, added)
// 11、移除旧 owners 对应的 dependents
gb.removeDependentFromOwners(existingNode, removed)
}
// 12、检查是否处于删除状态
if beingDeleted(accessor) {
existingNode.markBeingDeleted()
}
// 13、检查并处理 node 的删除操作
gb.processTransitions(event.oldObj, accessor, existingNode)
// 14、若为 delete event
case event.eventType == deleteEvent:
if !found {
return true
}
// 15、从 uidToNode 中删除该 node
gb.removeNode(existingNode)
existingNode.dependentsLock.RLock()
defer existingNode.dependentsLock.RUnlock()
if len(existingNode.dependents) > 0 {
gb.absentOwnerCache.Add(accessor.GetUID())
}
// 16、删除该 node 的 dependents
for dep := range existingNode.dependents {
gb.attemptToDelete.Add(dep)
}
// 17、删除该 node 处于删除阻塞状态的 owner
for _, owner := range existingNode.owners {
ownerNode, found := gb.uidToNode.Read(owner.UID)
if !found || !ownerNode.isDeletingDependents() {
continue
}
gb.attemptToDelete.Add(ownerNode)
}
}
return true
}
processTransitions
上述在处理 add 或 update event 时最后都调用了 processTransitions 方法检查 node 是否处于删除状态,若处于删除状态会通过其删除策略将 node 放到 attemptToOrphan 或 attemptToDelete 队列中。
k8s.io/kubernetes/pkg/controller/garbagecollector/graph_builder.go:509
func (gb *GraphBuilder) processTransitions(oldObj interface{}, newAccessor metav1.Object, n *node) {
if startsWaitingForDependentsOrphaned(oldObj, newAccessor) {
gb.attemptToOrphan.Add(n)
return
}
if startsWaitingForDependentsDeleted(oldObj, newAccessor) {
n.markDeletingDependents()
for dep := range n.dependents {
gb.attemptToDelete.Add(dep)
}
gb.attemptToDelete.Add(n)
}
}
gc.runAttemptToDeleteWorker
runAttemptToDeleteWorker 是执行删除 attemptToDelete 中 node 的方法,其主要逻辑为:
- 1、调用
gc.attemptToDeleteItem删除 node; - 2、若删除失败则重新加入到 attemptToDelete 队列中进行重试;
k8s.io/kubernetes/pkg/controller/garbagecollector/garbagecollector.go:280
func (gc *GarbageCollector) runAttemptToDeleteWorker() {
for gc.attemptToDeleteWorker() {
}
}
func (gc *GarbageCollector) attemptToDeleteWorker() bool {
item, quit := gc.attemptToDelete.Get()
gc.workerLock.RLock()
defer gc.workerLock.RUnlock()
if quit {
return false
}
defer gc.attemptToDelete.Done(item)
n, ok := item.(*node)
if !ok {
utilruntime.HandleError(fmt.Errorf("expect *node, got %#v", item))
return true
}
err := gc.attemptToDeleteItem(n)
if err != nil {
if _, ok := err.(*restMappingError); ok {
klog.V(5).Infof("error syncing item %s: %v", n, err)
} else {
utilruntime.HandleError(fmt.Errorf("error syncing item %s: %v", n, err))
}
gc.attemptToDelete.AddRateLimited(item)
} else if !n.isObserved() {
gc.attemptToDelete.AddRateLimited(item)
}
return true
}
gc.runAttemptToDeleteWorker 中调用了 gc.attemptToDeleteItem 执行实际的删除操作。
gc.attemptToDeleteItem
gc.attemptToDeleteItem 的主要逻辑为:
- 1、判断 node 是否处于删除状态;
- 2、从 apiserver 获取该 node 最新的状态,该 node 可能为 virtual node,若为 virtual node 则从 apiserver 中获取不到该 node 的对象,此时会将该 node 重新加入到 graphChanges 队列中,再次处理该 node 时会将其从 uidToNode 中删除;
- 3、判断该 node 最新状态的 uid 是否等于本地缓存中的 uid,若不匹配说明该 node 已更新过此时将其设置为 virtual node 并重新加入到 graphChanges 队列中,再次处理该 node 时会将其从 uidToNode 中删除;
4、通过 node 的
deletingDependents字段判断该 node 当前是否处于删除 dependents 的状态,若该 node 处于删除 dependents 的状态则调用processDeletingDependentsItem方法检查 node 的blockingDependents是否被完全删除,若blockingDependents已完全被删除则删除该 node 对应的 finalizer,若blockingDependents还未删除完,将未删除的blockingDependents加入到 attemptToDelete 中;上文中在 GraphBuilder 处理 graphChanges 中的事件时,若发现 node 处于删除状态,会将 node 的 dependents 加入到 attemptToDelete 中并标记 node 的
deletingDependents为 true;- 5、调用
gc.classifyReferences将 node 的ownerReferences分类为solid,dangling,waitingForDependentsDeletion三类:dangling(owner 不存在)、waitingForDependentsDeletion(owner 存在,owner 处于删除状态且正在等待其 dependents 被删除)、solid(至少有一个 owner 存在且不处于删除状态); - 6、对以上分类进行不同的处理,若
solid不为 0 即当前 node 至少存在一个 owner,该对象还不能被回收,此时需要将dangling和waitingForDependentsDeletion列表中的 owner 从 node 的ownerReferences删除,即已经被删除或等待删除的引用从对象中删掉; - 7、第二种情况是该 node 的 owner 处于
waitingForDependentsDeletion状态并且 node 的 dependents 未被完全删除,该 node 需要等待删除完所有的 dependents 后才能被删除; - 8、第三种情况就是该 node 已经没有任何 dependents 了,此时按照 node 中声明的删除策略调用 apiserver 的接口删除即可;
k8s.io/kubernetes/pkg/controller/garbagecollector/garbagecollector.go:404
func (gc *GarbageCollector) attemptToDeleteItem(item *node) error {
// 1、判断 node 是否处于删除状态
if item.isBeingDeleted() && !item.isDeletingDependents() {
return nil
}
// 2、从 apiserver 获取该 node 最新的状态
latest, err := gc.getObject(item.identity)
switch {
case errors.IsNotFound(err):
gc.dependencyGraphBuilder.enqueueVirtualDeleteEvent(item.identity)
item.markObserved()
return nil
case err != nil:
return err
}
// 3、判断该 node 最新状态的 uid 是否等于本地缓存中的 uid
if latest.GetUID() != item.identity.UID {
gc.dependencyGraphBuilder.enqueueVirtualDeleteEvent(item.identity)
item.markObserved()
return nil
}
// 4、判断该 node 当前是否处于删除 dependents 状态中
if item.isDeletingDependents() {
return gc.processDeletingDependentsItem(item)
}
// 5、检查 node 是否还存在 ownerReferences
ownerReferences := latest.GetOwnerReferences()
if len(ownerReferences) == 0 {
return nil
}
// 6、对 ownerReferences 进行分类
solid, dangling, waitingForDependentsDeletion, err := gc.classifyReferences(item, ownerReferences)
if err != nil {
return err
}
switch {
// 7、存在不处于删除状态的 owner
case len(solid) != 0:
if len(dangling) == 0 && len(waitingForDependentsDeletion) == 0 {
return nil
}
ownerUIDs := append(ownerRefsToUIDs(dangling), ownerRefsToUIDs(waitingForDependentsDeletion)...)
patch := deleteOwnerRefStrategicMergePatch(item.identity.UID, ownerUIDs...)
_, err = gc.patch(item, patch, func(n *node) ([]byte, error) {
return gc.deleteOwnerRefJSONMergePatch(n, ownerUIDs...)
})
return err
// 8、node 的 owner 处于 waitingForDependentsDeletion 状态并且 node
// 的 dependents 未被完全删除
case len(waitingForDependentsDeletion) != 0 && item.dependentsLength() != 0:
deps := item.getDependents()
// 9、删除 dependents
for _, dep := range deps {
if dep.isDeletingDependents() {
patch, err := item.unblockOwnerReferencesStrategicMergePatch()
if err != nil {
return err
}
if _, err := gc.patch(item, patch, gc.unblockOwnerReferencesJSONMergePatch); err != nil {
return err
}
break
}
}
// 10、以 Foreground 模式删除 node 对象
policy := metav1.DeletePropagationForeground
return gc.deleteObject(item.identity, &policy)
// 11、该 node 已经没有任何依赖了,按照 node 中声明的删除策略调用 apiserver 的接口删除
default:
var policy metav1.DeletionPropagation
switch {
case hasOrphanFinalizer(latest):
policy = metav1.DeletePropagationOrphan
case hasDeleteDependentsFinalizer(latest):
policy = metav1.DeletePropagationForeground
default:
policy = metav1.DeletePropagationBackground
}
return gc.deleteObject(item.identity, &policy)
}
}
gc.runAttemptToOrphanWorker
runAttemptToOrphanWorker 是处理以 orphan 模式删除的 node,主要逻辑为:
- 1、调用
gc.orphanDependents删除 owner 所有 dependentsOwnerReferences中的 owner 字段; - 2、调用
gc.removeFinalizer删除 owner 的orphanFinalizer; - 3、以上两步中若有失败的会进行重试;
k8s.io/kubernetes/pkg/controller/garbagecollector/garbagecollector.go:574
func (gc *GarbageCollector) runAttemptToOrphanWorker() {
for gc.attemptToOrphanWorker() {
}
}
func (gc *GarbageCollector) attemptToOrphanWorker() bool {
item, quit := gc.attemptToOrphan.Get()
gc.workerLock.RLock()
defer gc.workerLock.RUnlock()
if quit {
return false
}
defer gc.attemptToOrphan.Done(item)
owner, ok := item.(*node)
if !ok {
return true
}
owner.dependentsLock.RLock()
dependents := make([]*node, 0, len(owner.dependents))
for dependent := range owner.dependents {
dependents = append(dependents, dependent)
}
owner.dependentsLock.RUnlock()
err := gc.orphanDependents(owner.identity, dependents)
if err != nil {
gc.attemptToOrphan.AddRateLimited(item)
return true
}
// 更新 owner, 从 finalizers 列表中移除 "orphaningFinalizer"
err = gc.removeFinalizer(owner, metav1.FinalizerOrphanDependents)
if err != nil {
gc.attemptToOrphan.AddRateLimited(item)
}
return true
}
garbageCollector.Sync
garbageCollector.Sync 是 startGarbageCollectorController 中的第三个核心方法,主要功能是周期性的查询集群中所有的资源,过滤出 deletableResources,然后对比已经监控的 deletableResources 和当前获取到的 deletableResources 是否一致,若不一致则更新 GraphBuilder 的 monitors 并重新启动 monitors 监控所有的 deletableResources,该方法的主要逻辑为:
- 1、通过调用
GetDeletableResources获取集群内所有的deletableResources作为 newResources,deletableResources指支持 "delete", "list", "watch" 三种操作的 resource,包括 CR; - 2、检查 oldResources, newResources 是否一致,不一致则需要同步;
- 3、调用
gc.resyncMonitors同步 newResources,在gc.resyncMonitors中会重新调用 GraphBuilder 的syncMonitors和startMonitors两个方法完成 monitors 的刷新; - 4、等待 newResources informer 中的 cache 同步完成;
- 5、将 newResources 作为 oldResources,继续进行下一轮的同步;
k8s.io/kubernetes/pkg/controller/garbagecollector/garbagecollector.go:164
func (gc *GarbageCollector) Sync(discoveryClient discovery.ServerResourcesInterface, period time.Duration, stopCh <-chan struct{}) {
oldResources := make(map[schema.GroupVersionResource]struct{})
wait.Until(func() {
// 1、获取集群内所有的 DeletableResources 作为 newResources
newResources := GetDeletableResources(discoveryClient)
if len(newResources) == 0 {
return
}
// 2、判断集群中的资源是否有变化
if reflect.DeepEqual(oldResources, newResources) {
return
}
gc.workerLock.Lock()
defer gc.workerLock.Unlock()
// 3、开始更新 GraphBuilder 中的 monitors
attempt := 0
wait.PollImmediateUntil(100*time.Millisecond, func() (bool, error) {
attempt++
if attempt > 1 {
newResources = GetDeletableResources(discoveryClient)
if len(newResources) == 0 {
return false, nil
}
}
gc.restMapper.Reset()
// 4、调用 gc.resyncMonitors 同步 newResources
if err := gc.resyncMonitors(newResources); err != nil {
return false, nil
}
// 5、等待所有 monitors 的 cache 同步完成
if !cache.WaitForNamedCacheSync("garbage collector", waitForStopOrTimeout(stopCh, period), gc.dependencyGraphBuilder.IsSynced) {
return false, nil
}
return true, nil
}, stopCh)
// 6、更新 oldResources
oldResources = newResources
}, period, stopCh)
}
garbageCollector.Sync 中主要调用了两个方法,一是调用 GetDeletableResources 获取集群中所有的可删除资源,二是调用 gc.resyncMonitors 更新 GraphBuilder 中 monitors。
GetDeletableResources
在 GetDeletableResources 中首先通过调用 discoveryClient.ServerPreferredResources 方法获取集群内所有的 resource 信息,然后通过调用 discovery.FilteredBy 过滤出支持 "delete", "list", "watch" 三种方法的 resource 作为 deletableResources。
k8s.io/kubernetes/pkg/controller/garbagecollector/garbagecollector.go:636
func GetDeletableResources(discoveryClient discovery.ServerResourcesInterface) map[schema.GroupVersionResource]struct{} {
// 1、调用 discoveryClient.ServerPreferredResources 方法获取集群内所有的 resource 信息
preferredResources, err := discoveryClient.ServerPreferredResources()
if err != nil {
if discovery.IsGroupDiscoveryFailedError(err) {
......
} else {
......
}
}
if preferredResources == nil {
return map[schema.GroupVersionResource]struct{}{}
}
// 2、调用 discovery.FilteredBy 过滤出 deletableResources
deletableResources := discovery.FilteredBy(discovery.SupportsAllVerbs{Verbs: []string{"delete", "list", "watch"}}, preferredResources)
deletableGroupVersionResources := map[schema.GroupVersionResource]struct{}{}
for _, rl := range deletableResources {
gv, err := schema.ParseGroupVersion(rl.GroupVersion)
if err != nil {
continue
}
for i := range rl.APIResources {
deletableGroupVersionResources[schema.GroupVersionResource{Group: gv.Group, Version: gv.Version, Resource: rl.APIResources[i].Name}] = struct{}{}
}
}
return deletableGroupVersionResources
}
ServerPreferredResources
ServerPreferredResources 的主要功能是获取集群内所有的 resource 以及其 group、version、verbs 信息,该方法的主要逻辑为:
- 1、调用
ServerGroups方法获取集群内所有的 GroupList,ServerGroups方法首先从 apiserver 通过/apiURL 获取当前版本下所有可用的APIVersions,再通过/apisURL 获取 所有可用的APIVersions以及其下的所有APIGroupList; - 2、调用
fetchGroupVersionResources通过 serverGroupList 再获取到对应的 resource; - 3、将获取到的 version、group、resource 构建成标准格式添加到
metav1.APIResourceList中;
k8s.io/kubernetes/staging/src/k8s.io/client-go/discovery/discovery_client.go:285
func ServerPreferredResources(d DiscoveryInterface) ([]*metav1.APIResourceList, error) {
// 1、获取集群内所有的 GroupList
serverGroupList, err := d.ServerGroups()
if err != nil {
return nil, err
}
// 2、通过 serverGroupList 获取到对应的 resource
groupVersionResources, failedGroups := fetchGroupVersionResources(d, serverGroupList)
result := []*metav1.APIResourceList{}
grVersions := map[schema.GroupResource]string{} // selected version of a GroupResource
grAPIResources := map[schema.GroupResource]*metav1.APIResource{} // selected APIResource for a GroupResource
gvAPIResourceLists := map[schema.GroupVersion]*metav1.APIResourceList{} // blueprint for a APIResourceList for later grouping
// 3、格式化 resource
for _, apiGroup := range serverGroupList.Groups {
for _, version := range apiGroup.Versions {
groupVersion := schema.GroupVersion{Group: apiGroup.Name, Version: version.Version}
apiResourceList, ok := groupVersionResources[groupVersion]
if !ok {
continue
}
emptyAPIResourceList := metav1.APIResourceList{
GroupVersion: version.GroupVersion,
}
gvAPIResourceLists[groupVersion] = &emptyAPIResourceList
result = append(result, &emptyAPIResourceList)
for i := range apiResourceList.APIResources {
apiResource := &apiResourceList.APIResources[i]
if strings.Contains(apiResource.Name, "/") {
continue
}
gv := schema.GroupResource{Group: apiGroup.Name, Resource: apiResource.Name}
if _, ok := grAPIResources[gv]; ok && version.Version != apiGroup.PreferredVersion.Version {
continue
}
grVersions[gv] = version.Version
grAPIResources[gv] = apiResource
}
}
}
for groupResource, apiResource := range grAPIResources {
version := grVersions[groupResource]
groupVersion := schema.GroupVersion{Group: groupResource.Group, Version: version}
apiResourceList := gvAPIResourceLists[groupVersion]
apiResourceList.APIResources = append(apiResourceList.APIResources, *apiResource)
}
if len(failedGroups) == 0 {
return result, nil
}
return result, &ErrGroupDiscoveryFailed{Groups: failedGroups}
}
GetDeletableResources 方法中的调用流程为:
|--> d.ServerGroups
|
|--> discoveryClient. --|
| ServerPreferredResources |
| |--> fetchGroupVersionResources
GetDeletableResources --|
|
|--> discovery.FilteredBy
gc.resyncMonitors
gc.resyncMonitors 的主要功能是更新 GraphBuilder 的 monitors 并重新启动 monitors 监控所有的 deletableResources,GraphBuilder 的 syncMonitors 和 startMonitors 方法在前面的流程中已经分析过,此处不再详细说明。
k8s.io/kubernetes/pkg/controller/garbagecollector/garbagecollector.go:116
func (gc *GarbageCollector) resyncMonitors(deletableResources map[schema. GroupVersionResource]struct{}) error {
if err := gc.dependencyGraphBuilder.syncMonitors(deletableResources); err != nil {
return err
}
gc.dependencyGraphBuilder.startMonitors()
return nil
}
garbagecollector.NewDebugHandler
garbagecollector.NewDebugHandler 主要功能是对外提供一个接口供用户查询当前集群中所有资源的依赖关系,依赖关系可以以图表的形式展示。
func startGarbageCollectorController(ctx ControllerContext) (http.Handler, bool, error) {
......
return garbagecollector.NewDebugHandler(garbageCollector), true, nil
}
具体使用方法如下所示:
$ curl http://192.168.99.108:10252/debug/controllers/garbagecollector/graph > tmp.dot
$ curl http://192.168.99.108:10252/debug/controllers/garbagecollector/graph\?uid=f9555d53-2b5f-4702-9717-54a313ed4fe8 > tmp.dot
// 生成 svg 文件
$ dot -Tsvg -o graph.svg tmp.dot
// 然后在浏览器中打开 svg 文件
依赖关系图如下所示:
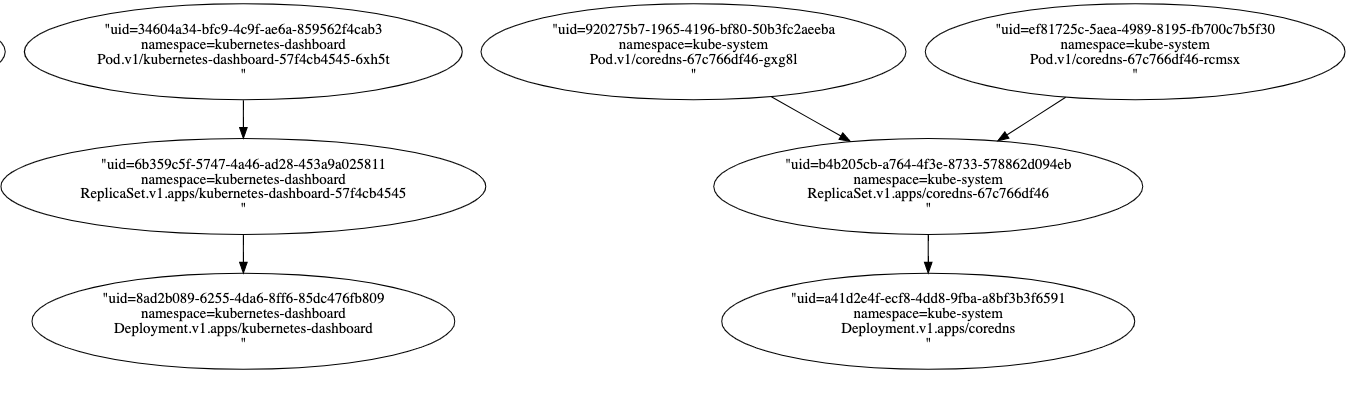
示例
在此处会有一个小示例验证一下源码中的删除阻塞逻辑,当以 Foreground 策略删除一个对象时,该对象会处于阻塞状态等待其依依赖被删除,此时有三种方式避免该对象处于删除阻塞状态,一是将依赖对象直接删除,二是将依赖对象自身的 OwnerReferences 中 owner 字段删除,三是将该依赖对象 OwnerReferences 字段中对应 owner 的 BlockOwnerDeletion 设置为 false,下面会验证下这三种方式,首先创建一个 deployment,deployment 创建出的 rs 默认不会有 foregroundDeletion finalizers,此时使用 kubectl edit 手动加上 foregroundDeletion finalizers,当 deployment 正常运行时,如下所示:
$ kubectl get deployment nginx-deployment
NAME READY UP-TO-DATE AVAILABLE AGE
nginx-deployment 2/2 2 2 43s
$ kubectl get rs nginx-deployment-69b6b4c5cd
NAME DESIRED CURRENT READY AGE
nginx-deployment-69b6b4c5cd 2 2 2 57s
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-deployment-69b6b4c5cd-26dsn 1/1 Running 0 66s
nginx-deployment-69b6b4c5cd-6rqqc 1/1 Running 0 64s
$ kubectl edit rs nginx-deployment-69b6b4c5cd
// deployment 关联的 rs 对象
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: nginx-deployment-69b6b4c5cd
namespace: default
ownerReferences:
- apiVersion: apps/v1
blockOwnerDeletion: true
controller: true
kind: Deployment
name: nginx-deployment
uid: 40a1044e-03d1-48bc-8806-cb79d781c946
finalizers:
- foregroundDeletion // 为 rs 手动添加的 Foreground 策略
......
spec:
replicas: 2
......
status:
......
当 deployment、rs、pod 都处于正常运行状态且 deployment 关联的 rs 使用 Foreground 删除策略时,然后验证源码中提到的三种方法,验证时需要模拟一个依赖对象无法删除的场景,当然这个也很好模拟,三种场景如下所示:
- 1、当 pod 所在的 node 处于 Ready 状态时,以
Foreground策略删除 deploment,因为 rs 关联的 pod 会直接被删除,rs 也会被正常删除,此时 deployment 也会直接被删除; - 2、当 pod 所在的 node 处于 NotReady 状态时,以
Foreground策略删除 deploment,此时因 rs 关联的 pod 无法被删除,rs 会一直处于删除阻塞状态,deployment 由于 rs 无法被删除也会处于删除阻塞状态,此时更新 rs 去掉其ownerReferences中对应的 deployment 部分,deployment 会因无依赖对象被成功删除; - 3、和 2 同样的场景,node 处于 NotReady 状态时,以
Foreground策略删除 deploment,deployment 和 rs 将处于删除阻塞状态,此时将 rsownerReferences中关联 deployment 的blockOwnerDeletion字段设置为 false,可以看到 deployment 会因无 block 依赖对象被成功删除;
$ systemctl stop kubelet
// node 处于 NotReady 状态
$ kubectl get node
NAME STATUS ROLES AGE VERSION
minikube NotReady master 6d11h v1.16.2
// 以 Foreground 策略删除 deployment
$ curl -k -v -XDELETE -H "Accept: application/json" -H "Content-Type: application/json" -d '{"propagationPolicy":"Foreground"}' 'https://192.168.99.108:8443/apis/apps/v1/namespaces/default/deployments/nginx-deployment'
总结
GarbageCollectorController 是一种典型的生产者消费者模型,所有 deletableResources 的 informer 都是生产者,每种资源的 informer 监听到变化后都会将对应的事件 push 到 graphChanges 中,graphChanges 是 GraphBuilder 对象中的一个数据结构,GraphBuilder 会启动另外的 goroutine 对 graphChanges 中的事件进行分类并放在其 attemptToDelete 和 attemptToOrphan 两个队列中,garbageCollector 会启动多个 goroutine 对 attemptToDelete 和 attemptToOrphan 两个队列中的事件进行处理,处理的结果就是回收一些需要被删除的对象。最后,再用一个流程图总结一下 GarbageCollectorController 的主要流程:
monitors (producer)
|
|
∨
graphChanges queue
|
|
∨
processGraphChanges
|
|
∨
-------------------------------
| |
| |
∨ ∨
attemptToDelete queue attemptToOrphan queue
| |
| |
∨ ∨
AttemptToDeleteWorker AttemptToOrphanWorker
(consumer) (consumer)