变量内存分配与回收
Go 程序会在两个地方为变量分配内存,一个是全局的堆上,另一个是函数调用栈,Go 语言有垃圾回收机制,在Go中变量分配在堆还是栈上是由编译器决定的,因此开发者无需过多关注变量是分配在栈上还是堆上。但如果想写出高质量的代码,了解语言背后的实现是有必要的,变量在栈上分配和在堆上分配底层实现的机制完全不同,变量的分配与回收流程不同,性能差异是非常大的。
堆与栈的区别
堆
程序运行时动态分配的内存都位于堆中,这部分内存由内存分配器负责管理,该区域的大小会随着程序的运行而变化,即当我们向堆请求分配内存但分配器发现堆中的内存不足时,它会向操作系统内核申请向高地址方向扩展堆的大小,而当我们释放内存把它归还给堆时如果内存分配器发现剩余空闲内存太多则又会向操作系统请求向低地址方向收缩堆的大小,从内存申请和释放流程可以看出,从堆上分配的内存用完之后必须归还给堆,否则内存分配器可能会反复向操作系统申请扩展堆的大小从而导致堆内存越用越多,最后出现内存不足,这就是所谓的内存泄漏。值的一提的是传统的 c/c++ 代码需要手动处理内存的分配和释放,而在 Go 语言中,有垃圾回收器来回收堆上的内存,所以程序员只管申请内存,而不用管内存的释放,大大降低了程序员的心智负担,这不光是提高了程序员的生产力,更重要的是还会减少很多bug的产生。
栈
函数调用栈简称栈,在程序运行过程中,不管是函数的执行还是函数调用,栈都起着非常重要的作用,它主要被用来:
- 保存函数的局部变量;
- 向被调用函数传递的参数;
- 返回函数的返回值;
- 保存函数的返回地址,返回地址是指从被调用函数返回后调用者应该继续执行的指令地址;
- 寄存器的初始值;
每个函数在执行过程中都需要使用一块栈内存用来保存上述这些值,我们称这块栈内存为某函数的栈帧(stack frame)。当发生函数调用时,因为调用者还没有执行完,其栈内存中保存的数据还有用,所以被调用函数不能覆盖调用者的栈帧,只能把被调用函数的栈帧“push”到栈上,等被调函数执行完成后再把其栈帧从栈上“pop”出去,这样,栈的大小就会随函数调用层级的增加而生长,随函数的返回而缩小,也就是说函数调用层级越深,消耗的栈空间就越大。栈的生长和收缩都是自动的,由编译器插入的代码自动完成,因此位于栈内存中的函数局部变量所使用的内存随函数的调用而分配,随函数的返回而自动释放,所以程序员不管是使用有垃圾回收还是没有垃圾回收的高级编程语言都不需要自己释放局部变量所使用的内存,这一点与堆上分配的内存截然不同。
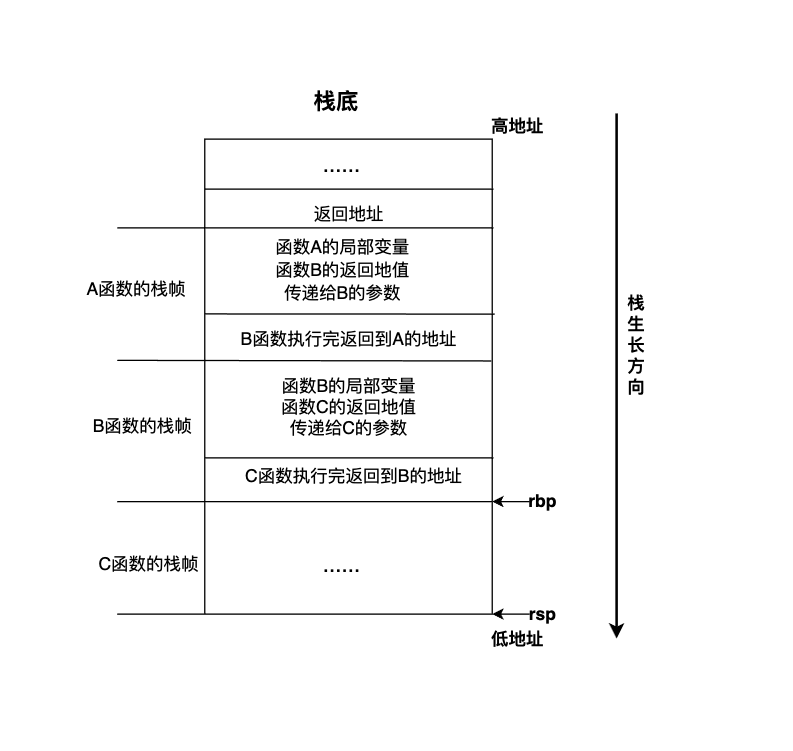
进程是操作系统资源分配的基本单位,每个进程在启动时操作系统会进程的栈分配固定大小的内存,Linux 中进程默认栈的大小可以通过 ulimit -s 查看,当函数退出时分配在栈上的内存通过修改寄存器指针的偏移量会自动进行回收,进程在运行时堆中内存的大小都需要向操作系统申请,进程堆可用内存的大小也取决于当前操作系统可用内存的量。
那么在 Go 中变量分配在堆上与栈上编译器是如何决定的?
变量内存分配逃逸分析
上文已经提到 Go 中变量分配在堆还是栈上是由编译器决定的,这种由编译器决定内存分配位置的方式称之为逃逸分析(escape analysis)。Go 中声明一个函数内局部变量时,当编译器发现变量的作用域没有逃出函数范围时,就会在栈上分配内存,反之则分配在堆上,逃逸分析由编译器完成,作用于编译阶段。
检查该变量是在栈上分配还是堆上分配
有两种方式可以确定变量是在堆还是在栈上分配内存:
- 通过编译后生成的汇编函数来确认,在堆上分配内存的变量都会调用 runtime 包的
newobject函数; - 编译时通过指定选项显示编译优化信息,编译器会输出逃逸的变量;
通过以上两种方式来分析以下代码示例中的变量是否存在逃逸:
package main
type demo struct {
Msg string
}
func example() *demo {
d := &demo{}
return d
}
func main() {
example()
}
1、通过汇编来确认变量内存分配是否有逃逸
$ go tool compile -S main.go
go tool compile -S main.go
"".example STEXT size=72 args=0x8 locals=0x18
0x0000 00000 (main.go:7) TEXT "".example(SB), ABIInternal, $24-8
0x0000 00000 (main.go:7) MOVQ (TLS), CX
0x0009 00009 (main.go:7) CMPQ SP, 16(CX)
0x000d 00013 (main.go:7) PCDATA $0, $-2
0x000d 00013 (main.go:7) JLS 65
0x000f 00015 (main.go:7) PCDATA $0, $-1
0x000f 00015 (main.go:7) SUBQ $24, SP
0x0013 00019 (main.go:7) MOVQ BP, 16(SP)
0x0018 00024 (main.go:7) LEAQ 16(SP), BP
0x001d 00029 (main.go:7) PCDATA $0, $-2
0x001d 00029 (main.go:7) PCDATA $1, $-2
0x001d 00029 (main.go:7) FUNCDATA $0, gclocals·9fb7f0986f647f17cb53dda1484e0f7a(SB)
0x001d 00029 (main.go:7) FUNCDATA $1, gclocals·69c1753bd5f81501d95132d08af04464(SB)
0x001d 00029 (main.go:7) FUNCDATA $2, gclocals·9fb7f0986f647f17cb53dda1484e0f7a(SB)
0x001d 00029 (main.go:8) PCDATA $0, $1
0x001d 00029 (main.go:8) PCDATA $1, $0
0x001d 00029 (main.go:8) LEAQ type."".demo(SB), AX
0x0024 00036 (main.go:8) PCDATA $0, $0
0x0024 00036 (main.go:8) MOVQ AX, (SP)
0x0028 00040 (main.go:8) CALL runtime.newobject(SB) // 调用 runtime.newobject 函数
0x002d 00045 (main.go:8) PCDATA $0, $1
0x002d 00045 (main.go:8) MOVQ 8(SP), AX
0x0032 00050 (main.go:9) PCDATA $0, $0
0x0032 00050 (main.go:9) PCDATA $1, $1
0x0032 00050 (main.go:9) MOVQ AX, "".~r0+32(SP)
0x0037 00055 (main.go:9) MOVQ 16(SP), BP
0x003c 00060 (main.go:9) ADDQ $24, SP
0x0040 00064 (main.go:9) RET
0x0041 00065 (main.go:9) NOP
0x0041 00065 (main.go:7) PCDATA $1, $-1
0x0041 00065 (main.go:7) PCDATA $0, $-2
0x0041 00065 (main.go:7) CALL runtime.morestack_noctxt(SB)
0x0046 00070 (main.go:7) PCDATA $0, $-1
0x0046 00070 (main.go:7) JMP 0
以上仅仅列出了 example 函数编译后的汇编代码,可以看到在程序的第8行调用了 runtime.newobject 函数。
2、通过编译选项检查
执行 go tool compile -l -m -m main.go 或者 go build -gcflags "-m -m -l" main.go
$ go build -gcflags "-m -l" main.go
# command-line-arguments
./main.go:8:7: &demo literal escapes to heap:
./main.go:8:7: flow: d = &{storage for &demo literal}:
./main.go:8:7: from &demo literal (spill) at ./main.go:8:7
./main.go:8:7: from d := &demo literal (assign) at ./main.go:8:4
./main.go:8:7: flow: ~r0 = d:
./main.go:8:7: from return d (return) at ./main.go:9:2
./main.go:8:7: &demo literal escapes to heap
$ go tool compile -l -m -m main.go
main.go:8:7: &demo literal escapes to heap:
main.go:8:7: flow: d = &{storage for &demo literal}:
main.go:8:7: from &demo literal (spill) at main.go:8:7
main.go:8:7: from d := &demo literal (assign) at main.go:8:4
main.go:8:7: flow: ~r0 = d:
main.go:8:7: from return d (return) at main.go:9:2
main.go:8:7: &demo literal escapes to heap
可以使用 go tool compile --help 查看几个选项的含义。
Go 官方 faq 文档 stack_or_heap 一节也说了如何知道一个变量是在堆上还是在粘上分配内存的,文档描述的比较简单,下面再看几个特定类型的示例。
函数内变量在堆上分配的一些 case
1、指针类型的变量,指针逃逸
代码示例,和上节示例一致:
package main
type demo struct {
Msg string
}
func example() *demo {
d := &demo{}
return d
}
func main() {
example()
}
$ go tool compile -l -m main.go
main.go:8:7: &demo literal escapes to heap
2、栈空间不足
package main
func generate8191() {
nums := make([]int, 8191) // < 64KB
for i := 0; i < 8191; i++ {
nums[i] = i
}
}
func generate8192() {
nums := make([]int, 8192) // = 64KB
for i := 0; i < 8192; i++ {
nums[i] = i
}
}
func generate(n int) {
nums := make([]int, n) // 不确定大小
for i := 0; i < n; i++ {
nums[i] = i
}
}
func main() {
generate8191()
generate8192()
generate(1)
}
$ go tool compile -l -m main.go
main.go:4:14: make([]int, 8191) does not escape
main.go:9:14: make([]int, 8192) escapes to heap
main.go:14:14: make([]int, n) escapes to heap
在 Go 编译器代码中可以看到,对于有声明类型的变量大小超过 10M 会被分配到堆上,隐式变量默认超过64KB 会被分配在堆上。
var (
// maximum size variable which we will allocate on the stack.
// This limit is for explicit variable declarations like "var x T" or "x := ...".
// Note: the flag smallframes can update this value.
maxStackVarSize = int64(10 * 1024 * 1024)
// maximum size of implicit variables that we will allocate on the stack.
// p := new(T) allocating T on the stack
// p := &T{} allocating T on the stack
// s := make([]T, n) allocating [n]T on the stack
// s := []byte("...") allocating [n]byte on the stack
// Note: the flag smallframes can update this value.
maxImplicitStackVarSize = int64(64 * 1024)
)
3、动态类型,interface{} 动态类型逃逸
package main
type Demo struct {
Name string
}
func main() {
_ = example()
}
func example() interface{} {
return Demo{}
}
$ go tool compile -l -m main.go
main.go:12:13: Demo literal escapes to heap
4、闭包引用对象
package main
import "fmt"
func increase(x int) func() int {
return func() int {
x++
return x
}
}
func main() {
x := 0
in := increase(x)
fmt.Println(in())
fmt.Println(in())
}
$ go tool compile -l -m main.go
main.go:5:15: moved to heap: x
main.go:6:9: func literal escapes to heap
main.go:15:13: ... argument does not escape
main.go:15:16: in() escapes to heap
main.go:16:13: ... argument does not escape
main.go:16:16: in() escapes to heap
函数使用值与指针返回时性能的差异
上文介绍了 Go 中变量内存分配方式,通过上文可以知道在函数中定义变量并使用值返回时,该变量会在栈上分配内存,函数返回时会拷贝整个对象,使用指针返回时变量在分配内存时会逃逸到堆中,返回时只会拷贝指针地址,最终变量会通过 Go 的垃圾回收机制回收掉。
那在函数中返回时是使用值还是指针,哪种效率更高呢,虽然值有拷贝操作,但是返回指针会将变量分配在堆上,堆上变量的分配以及回收也会有较大的开销。对于该问题,跟返回的对象和平台也有一定的关系,不同的平台需要通过基准测试才能得到一个比较准确的结果。
return_value_or_pointer.go
package main
import "fmt"
const bigSize = 200000
type bigStruct struct {
nums [bigSize]int
}
func newBigStruct() bigStruct {
var a bigStruct
for i := 0; i < bigSize; i++ {
a.nums[i] = i
}
return a
}
func newBigStructPtr() *bigStruct {
var a bigStruct
for i := 0; i < bigSize; i++ {
a.nums[i] = i
}
return &a
}
func main() {
a := newBigStruct()
b := newBigStructPtr()
fmt.Println(a, b)
}
benchmark_test.go
package main
import "testing"
func BenchmarkStructReturnValue(b *testing.B) {
b.ReportAllocs()
t := 0
for i := 0; i < b.N; i++ {
v := newBigStruct()
t += v.nums[0]
}
}
func BenchmarkStructReturnPointer(b *testing.B) {
b.ReportAllocs()
t := 0
for i := 0; i < b.N; i++ {
v := newBigStructPtr()
t += v.nums[0]
}
}
$ go test -bench .
goos: darwin
goarch: amd64
BenchmarkStructReturnValue-12 4215 278542 ns/op 0 B/op 0 allocs/op
BenchmarkStructReturnPointer-12 4556 267253 ns/op 1605634 B/op 1 allocs/op
PASS
ok _/Users/tianfeiyu/golang-dev/test 3.670s
在我本地测试中,200000 个 int 类型的结构体返回值更快些,小于 200000 时返回指针会更快。 如果对于代码有更高的性能要求,需要在实际平台上进行基准测试来得出结论。
其他的一些使用经验
1、有状态的对象必须使用指针返回,如系统内置的 sync.WaitGroup、sync.Pool 之类的值,在 Go 中有些结构体中会显式存在 noCopy 字段提醒不能进行值拷贝;
// A WaitGroup must not be copied after first use.
type WaitGroup struct {
noCopy noCopy
......
}
2、生命周期短的对象使用值返回,如果对象的生命周期存在比较久或者对象比较大,可以使用指针返回;
3、大对象推荐使用指针返回,对象大小临界值需要在具体平台进行基准测试得出数据;
4、参考一些大的开源项目中的使用方式,比如 kubernetes、docker 等;
总结
本文通过分析在 Go 函数中使用变量时的一些问题,变量在分配内存时会在堆和栈两个地方存在,在堆和栈上分配内存的不同,以及何时需要在堆上分配内存的变量。
参考:
https://mojotv.cn/go/bad-go-pointer-returns
https://github.com/eastany/eastany.github.com/issues/61
https://mp.weixin.qq.com/s/PXGCqxK97U8mLGxW07ZTqw
https://golang.design/under-the-hood/zh-cn/part1basic/ch01basic/asm/