knative 部署完成后可以在 knative-serving namespace 下看到创建出的组件:
1 | $ kubectl get pod -n knative-serving |
创建 knative serving
首先创建一个 knative service 进行测试,yaml 文件如下所示:
1 | // 创建 helloworld-go 示例: |
创建完成后验证一下 knative 的 kpa 功能,创建完 helloworld-go serving 后会存在一个 pod 实例,如果该 pod 长时间没有被访问则会被销毁。首先验证下首次请求 helloworld-go 的场景,当服务的实例被完全销毁后,请求 helloworld-go 的 URL 此时会先启动一个实例,如下所示:
1 | $ time curl -H "Host: helloworld-go.example.example.com" http://192.168.99.130:31046 |
使用 minkube 搭建的 k8s 集群由于没有 loadBalancer 此处使用 nodeport 来访问,nodeport 的 31046 端口会转发到后端实例的 8080 端口。当流量到达 helloworld-go 服务时,此时该服务还没有实例,activator 感知到请求后会对 helloworld-go 的 deployment 进行一次扩容,将 deployment 的 replicas 指定为 1,此时 helloworld-go deployment 会拉起一个 pod 实例,由于 pod 首次启动会比较慢。
在实际的环境中,当流量达到后再启动 pod 是不可接受的,一般会保留一个相同实例的 pod 或者一个配置较低的实例,避免冷启动时相应慢或者丢失流量等情况。
存在一个实例后,再次访问时可以看到整个请求流程非常快了,如下所示:
1 | $ time curl -H "Host: helloworld-go.example.example.com" http://192.168.99.130:31046 |
knative serving 组件
serving 共有 6 个主要的组件,其中 5 个在 knative-serving 这个 namespace 下面,分别为 controller 、webhook 、autoscaler、autoscaler-hpa、activator 这五个组件;还有一个 queue,运行在每个应用的 pod 里,作为 pod 的 sidecar 存在。
- 1、Controller:负载 Service 整个生命周期的管理,涉及、Configuration、Route、Revision 等的 CURD。是一个控制器,根据用户输入更新集群的状态;
- 2、Webhook:主要负责创建和更新的参数校验;
- 3、Activator:在应用缩容到 0 后,拦截用户的请求,通知 autoscaler 启动相应应用实例,等待启动后将请求转发。负责将服务缩容到 0 以及转发请求;
- 4、Autoscaler:根据应用的请求并发量对应用扩缩容;
- 5、Queue:负载拦截转发给 Pod 的请求,用于统计 Pod 的请求并发量等,autoscaler 会访问 queue 获取相应数据对应用扩缩容;
- 6、Autoscaler-hpa:负责 autoscaler 应用的扩缩容;
Knative 把应用里的所有能力全都放到统一的 CRD 资源中管理—Service。这里的 Service 与 K8s 原生用户访问的 Service 不同,这是 Knative 的自定义资源,管理 Knative 应用的整个生命周期。
- Service:service.serving.knative.dev 资源管理着工作负载的整个生命周期。它控制其他对象(Route、Configration、Revison)的创建,并确保每次对 Service 的更新都作用到其他对象。
- Route: route.serving.knative.dev 资源将网络端点映射到一个或多个 Revision。可以通过配置 Route 实现多种流量管理方式,包括部分流量和命名路由。
- Configuration:configuration.serving.knative.dev 资源保持部署所需的状态。它提供了代码和配置之间的清晰分离,并遵循十二要素应用程序方法。修改 Configuration 将创建新的 Revision。
- Revision:revision.serving.knative.dev 资源是对工作负荷所做的每个修改的代码和配置的时间点快照。修订是不变的对象,只要有用就可以保留。Revision 可以根据进入的流量自动扩缩容。
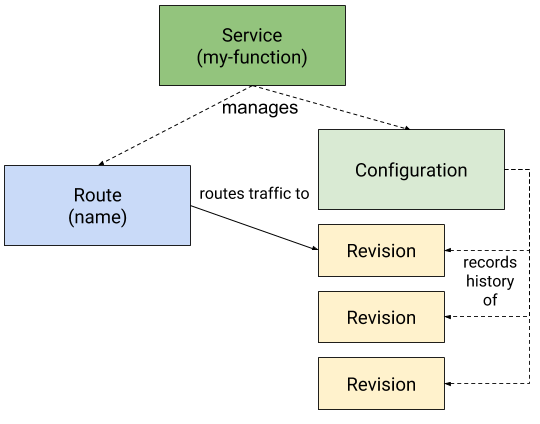
Serving 关联的所有资源如下图所示:
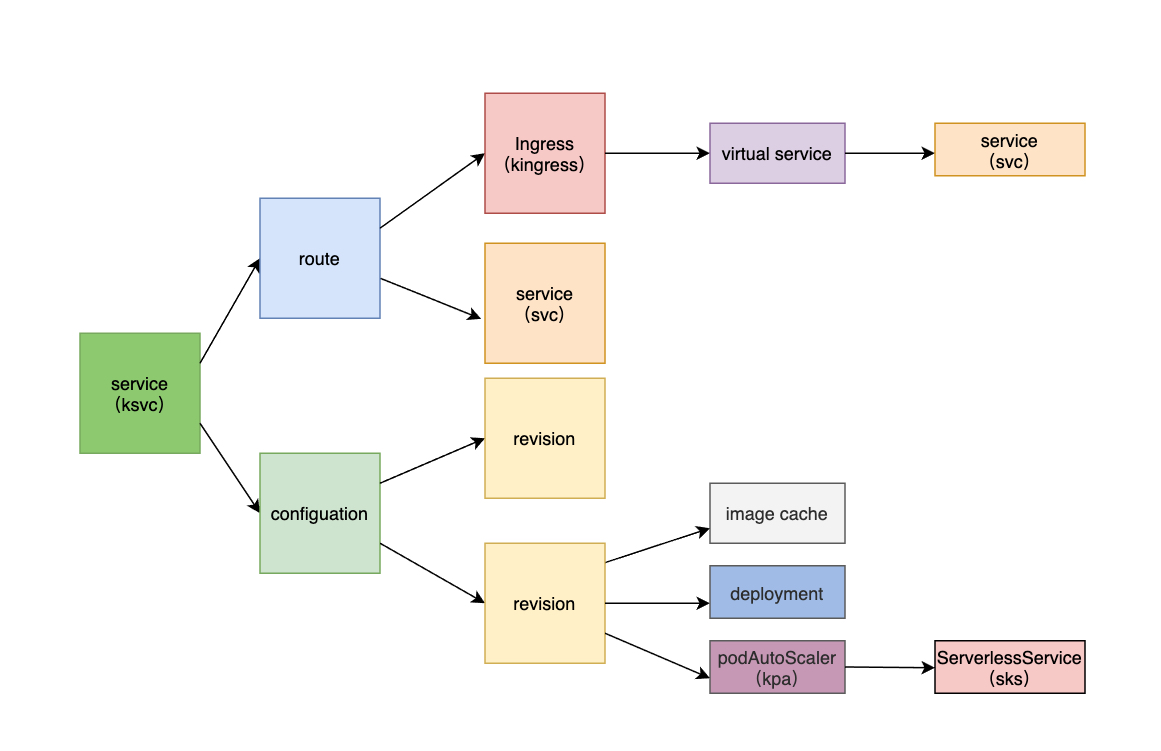
- 1、revision 会创建 imageCache、deployment、kpa 以及 sks 几个组件,deployment 是所运行的服务,kpa 会根据并发数进行伸缩对应的 deployment,ServerlessService 会为 kpa 服务在 cluster 内部和外部都创建一个可以访问的 service。image cache 主要是为了解决冷启动时拉取镜像慢的问题;
- 2、route 会创建 svc、kingress、virtualService 几个组件,供 service 之间以及从外部访问;
自动扩缩容
1->n: 任何访问应用的请求在进入 Pod 后都会被 Queue 拦截,统计当前 Pod 的请求并发数,同时 Queue 会开放一个 metric 接口,autoscalor 通过访问该端口去获取 Pod 的请求并发量并计算是否需要扩缩容。当需要扩缩容时,autoscalor 会通过修改 Revision 下的 deployment 的实例个数达到扩缩容的效果。
0->1: 在应用长时间无请求访问时,实例会缩减到 0。这个时候,访问应用的请求会被转发到 activator,并在请求在转发到 activator 之前会被标记请求访问的 Revision 信息(由 controller 修改 VirtualService 实现)。activator 接收到请求后,会将 Revision 的并发量加 1,并将 metric 推送给 autoscalor,启动 Pod。同时,activator 监控 Revision 的启动状态,Revision 正常启动后,将请求转发给相应的 Pod。
当然,在 Revision 正常启动后,应用的请求将不会再发送到 activator,而且直接发送至应用的 Pod(由 controller 修改 VirtualService 实现)。
在 mac 下使用 hey 进行压测,当请求数增加时对应服务的实例数同样会增加:
1 | $ hey -z 30s -c 50 -host "helloworld-go.example.example.com" http://192.168.99.130:31046 |
knative 网络模式
knative 目前默认使用 Istio 作为网络的基础,但 knative 不强依赖 istio,除 istio 之外,还可以选择 ambassador,contour,gloo,kourier 等。网络模式分两个部分,一个为 service 之间的访问,一个为外部访问。
service 之间的访问:
- istio 会解析 knative service 的 virtualService 下发给各个 pod 的 envoy,当应用通过域名相互访问时,envoy 会拦截请求直接转发给相应的 pod。
外部访问:
如果是在集群外访问,默认的请求入口为 ingressgateway,ingressgateway 将请求根据访问域名转发到应用,如上面示例所示,在本地搭建的 k8s 集群上访问 ingressgateway 的 nodeport,ingressgateway 会将请求转发到后端的 service;
如果是在集群节点上访问,每个 knative service 都对应一个 k8s service, 这个 service 的后端都为 ingressgateway,ingressgateway 会根据访问域名转发到应用;
knative 会给每一个 revision 都生成一个域名用于外部访问使用,service 默认的主域名是 example.com,所有 knative service 生成的独立域名都是这个主域名的子域名,可以通过修改 config 来指定默认域名:
1 | $ kubectl edit cm config-domain --namespace knative-serving |
参考:
https://knative.dev/docs/serving/
https://github.com/knative/docs/tree/master/docs/serving/samples/hello-world/helloworld-go