在前面的文章中已经分析过 kubernetes 中多个组件的源码了,本章会继续解读 kube-controller-manager 源码,kube-controller-manager 中有数十个 controller,本文会分析最常用到的 deployment controller。
deployment 的功能
deployment 是 kubernetes 中用来部署无状态应用的一个对象,也是最常用的一种对象。
deployment、replicaSet 和 pod 之间的关系
deployment 的本质是控制 replicaSet,replicaSet 会控制 pod,然后由 controller 驱动各个对象达到期望状态。
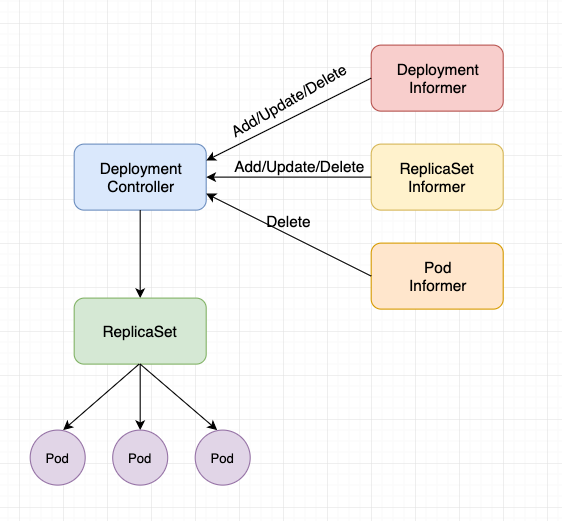
DeploymentController 是 Deployment 资源的控制器,其通过 DeploymentInformer、ReplicaSetInformer、PodInformer 监听三种资源,当三种资源变化时会触发 DeploymentController 中的 syncLoop 操作。
deployment 的基本功能
下面通过命令行操作展示一下 deployment 的基本功能。
以下是 deployment 的一个示例文件:
1 | apiVersion: apps/v1 |
创建
1 | $ kubectl create -f nginx-dep.yaml --record |
滚动更新
1 | $ kubectl set image deploy/nginx-deployment nginx-deployment=nginx:1.9.3 |
回滚
1 | // 查看历史版本 |
扩缩容
1 | $ kubectl scale deployment nginx-deployment --replicas 10 |
暂停与恢复
1 | $ kubectl rollout pause deployment/nginx-deployment |
删除
1 | // 级联删除 |
以上是 deployment 的几个常用操作,下面会结合源码分析这几个操作都是如何实现的。
deployment controller 源码分析
kubernetes 版本:v1.16
在控制器模式下,每次操作对象都会触发一次事件,然后 controller 会进行一次 syncLoop 操作,controller 是通过 informer 监听事件以及进行 ListWatch 操作的,关于 informer 的基础知识可以参考以前写的文章。
deployment controller 启动流程
kube-controller-manager 中所有 controller 的启动都是在 Run 方法中完成初始化并启动的。在 Run 中会调用 run 函数,run 函数的主要流程有:
- 1、调用
NewControllerInitializers初始化所有 controller - 2、调用
StartControllers启动所有 controller
k8s.io/kubernetes/cmd/kube-controller-manager/app/controllermanager.go:158
1 | func Run(c *config.CompletedConfig, stopCh <-chan struct{}) error { |
NewControllerInitializers 中定义了所有的 controller 以及 start controller 对应的方法。deployment controller 对应的启动方法是 startDeploymentController。
k8s.io/kubernetes/cmd/kube-controller-manager/app/controllermanager.go:373
1 | func NewControllerInitializers(loopMode ControllerLoopMode) map[string]InitFunc { |
在startDeploymentController 中对 deploymentController 进行了初始化,并执行 dc.Run() 方法启动了 controller。
k8s.io/kubernetes/cmd/kube-controller-manager/app/apps.go:82
1 | func startDeploymentController(ctx ControllerContext) (http.Handler, bool, error) { |
ctx.ComponentConfig.DeploymentController.ConcurrentDeploymentSyncs 指定了 deployment controller 中工作的 goroutine 数量,默认值为 5,即会启动五个 goroutine 从 workqueue 中取出 object 并进行 sync 操作,该参数的默认值定义在 k8s.io/kubernetes/pkg/controller/deployment/config/v1alpha1/defaults.go 中。
dc.Run 方法会执行 ListWatch 操作并根据对应的事件执行 syncLoop。
k8s.io/kubernetes/pkg/controller/deployment/deployment_controller.go:148
1 | func (dc *DeploymentController) Run(workers int, stopCh <-chan struct{}) { |
dc.worker 会调用 syncHandler 进行 sync 操作。
1 | func (dc *DeploymentController) worker() { |
syncHandler 是 controller 的核心逻辑,下面会进行详细说明。至此,对于 deployment controller 的启动流程已经分析完,再来看一下 deployment controller 启动过程中的整个调用链,如下所示:
1 | Run() --> run() --> NewControllerInitializers() --> StartControllers() --> startDeploymentController() --> deployment.NewDeploymentController() --> deployment.Run() |
deployment controller 在初始化时指定了 dc.syncHandler = dc.syncDeployment,所以该函数名为 syncDeployment,本文开头介绍 deployment 中的基本操作都是在 syncDeployment 中完成的。
syncDeployment 的主要流程如下所示:
- 1、调用
getReplicaSetsForDeployment获取集群中与 Deployment 相关的 ReplicaSet,若发现匹配但没有关联 deployment 的 rs 则通过设置 ownerReferences 字段与 deployment 关联,已关联但不匹配的则删除对应的 ownerReferences; - 2、调用
getPodMapForDeployment获取当前 Deployment 对象关联的 pod,并根据 rs.UID 对上述 pod 进行分类; - 3、通过判断 deployment 的 DeletionTimestamp 字段确认是否为删除操作;
- 4、执行
checkPausedConditions检查 deployment 是否为pause状态并添加合适的condition; - 5、调用
getRollbackTo函数检查 Deployment 是否有Annotations:"deprecated.deployment.rollback.to"字段,如果有,调用dc.rollback方法执行 rollback 操作; - 6、调用
dc.isScalingEvent方法检查是否处于 scaling 状态中; - 7、最后检查是否为更新操作,并根据更新策略
Recreate或RollingUpdate来执行对应的操作;
k8s.io/kubernetes/pkg/controller/deployment/deployment_controller.go:5621
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73func (dc *DeploymentController) syncDeployment(key string) error {
......
namespace, name, err := cache.SplitMetaNamespaceKey(key)
if err != nil {
return err
}
// 1、从 informer cache 中获取 deployment 对象
deployment, err := dc.dLister.Deployments(namespace).Get(name)
if errors.IsNotFound(err) {
......
}
......
d := deployment.DeepCopy()
// 2、判断 selecor 是否为空
everything := metav1.LabelSelector{}
if reflect.DeepEqual(d.Spec.Selector, &everything) {
......
return nil
}
// 3、获取 deployment 对应的所有 rs,通过 LabelSelector 进行匹配
rsList, err := dc.getReplicaSetsForDeployment(d)
if err != nil {
return err
}
// 4、获取当前 Deployment 对象关联的 pod,并根据 rs.UID 对 pod 进行分类
podMap, err := dc.getPodMapForDeployment(d, rsList)
if err != nil {
return err
}
// 5、如果该 deployment 处于删除状态,则更新其 status
if d.DeletionTimestamp != nil {
return dc.syncStatusOnly(d, rsList)
}
// 6、检查是否处于 pause 状态
if err = dc.checkPausedConditions(d); err != nil {
return err
}
if d.Spec.Paused {
return dc.sync(d, rsList)
}
// 7、检查是否为回滚操作
if getRollbackTo(d) != nil {
return dc.rollback(d, rsList)
}
// 8、检查 deployment 是否处于 scale 状态
scalingEvent, err := dc.isScalingEvent(d, rsList)
if err != nil {
return err
}
if scalingEvent {
return dc.sync(d, rsList)
}
// 9、更新操作
switch d.Spec.Strategy.Type {
case apps.RecreateDeploymentStrategyType:
return dc.rolloutRecreate(d, rsList, podMap)
case apps.RollingUpdateDeploymentStrategyType:
return dc.rolloutRolling(d, rsList)
}
return fmt.Errorf("unexpected deployment strategy type: %s", d.Spec.Strategy.Type)
}
可以看出对于 deployment 的删除、暂停恢复、扩缩容以及更新操作都是在 syncDeployment 方法中进行处理的,最终是通过调用 syncStatusOnly、sync、rollback、rolloutRecreate、rolloutRolling 这几个方法来处理的,其中 syncStatusOnly 和 sync 都是更新 Deployment 的 Status,rollback 是用来回滚的,rolloutRecreate 和 rolloutRolling 是根据不同的更新策略来更新 Deployment 的,下面就来看看这些操作的具体实现。
从 syncDeployment 中也可知以上几个操作的优先级为:
1 | delete > pause > rollback > scale > rollout |
举个例子,当在 rollout 操作时可以执行 pause 操作,在 pause 状态时也可直接执行删除操作。
删除
syncDeployment 中首先处理的是删除操作,删除操作是由客户端发起的,首先会在对象的 metadata 中设置 DeletionTimestamp 字段。
func (dc *DeploymentController) syncDeployment(key string) error {
......
if d.DeletionTimestamp != nil {
return dc.syncStatusOnly(d, rsList)
}
......
}
当 controller 检查到该对象有了 DeletionTimestamp 字段时会调用 dc.syncStatusOnly 执行对应的删除逻辑,该方法首先获取 newRS 以及所有的 oldRSs,然后会调用 syncDeploymentStatus 方法。
k8s.io/kubernetes/pkg/controller/deployment/sync.go:481
2
3
4
5
6
7
8
9func (dc *DeploymentController) syncStatusOnly(d *apps.Deployment, rsList []*apps.ReplicaSet) error {
newRS, oldRSs, err := dc.getAllReplicaSetsAndSyncRevision(d, rsList, false)
if err != nil {
return err
}
allRSs := append(oldRSs, newRS)
return dc.syncDeploymentStatus(allRSs, newRS, d)
}
syncDeploymentStatus 首先通过 newRS 和 allRSs 计算 deployment 当前的 status,然后和 deployment 中的 status 进行比较,若二者有差异则更新 deployment 使用最新的 status,syncDeploymentStatus 在后面的多种操作中都会被用到。
k8s.io/kubernetes/pkg/controller/deployment/sync.go:4691
2
3
4
5
6
7
8
9
10
11
12func (dc *DeploymentController) syncDeploymentStatus(allRSs []*apps.ReplicaSet, newRS *apps.ReplicaSet, d *apps.Deployment) error {
newStatus := calculateStatus(allRSs, newRS, d)
if reflect.DeepEqual(d.Status, newStatus) {
return nil
}
newDeployment := d
newDeployment.Status = newStatus
_, err := dc.client.AppsV1().Deployments(newDeployment.Namespace).UpdateStatus(newDeployment)
return err
}
calculateStatus 如下所示,主要是通过 allRSs 以及 deployment 的状态计算出最新的 status。
k8s.io/kubernetes/pkg/controller/deployment/sync.go:483
1 | func calculateStatus(allRSs []*apps.ReplicaSet, newRS *apps.ReplicaSet, deployment *apps.Deployment) apps.DeploymentStatus { |
以上就是 controller 中处理删除逻辑的主要流程,通过上述代码可知,当删除 deployment 对象时,仅仅是判断该对象中是否存在 metadata.DeletionTimestamp 字段,然后进行一次状态同步,并没有看到删除 deployment、rs、pod 对象的操作,其实删除对象并不是在此处进行而是在 kube-controller-manager 的垃圾回收器(garbagecollector controller)中完成的,对于 garbagecollector controller 会在后面的文章中进行说明,此外在删除对象时还需要指定一个删除选项(orphan、background 或者 foreground)来说明该对象如何删除。
暂停和恢复
暂停以及恢复两个操作都是通过更新 deployment spec.paused 字段实现的,下面直接看它的具体实现。
1 | func (dc *DeploymentController) syncDeployment(key string) error { |
当触发暂停操作时,会调用 sync 方法进行操作,sync 方法的主要逻辑如下所示:
- 1、获取 newRS 和 oldRSs;
- 2、根据 newRS 和 oldRSs 判断是否需要 scale 操作;
- 3、若处于暂停状态且没有执行回滚操作,则根据 deployment 的
.spec.revisionHistoryLimit中的值清理多余的 rs; - 4、最后执行
syncDeploymentStatus更新 status;
1 | func (dc *DeploymentController) sync(d *apps.Deployment, rsList []*apps.ReplicaSet) error { |
上文已经提到过 deployment controller 在一个 syncLoop 中各种操作是有优先级,而 pause > rollback > scale > rollout,通过文章开头的命令行参数也可以看出,暂停和恢复操作只有在 rollout 时才会生效,再结合源码分析,虽然暂停操作下不会执行到 scale 相关的操作,但是 pause 与 scale 都是调用 sync 方法完成的,且在 sync 方法中会首先检查 scale 操作是否完成,也就是说在 pause 操作后并不是立即暂停所有操作,例如,当执行滚动更新操作后立即执行暂停操作,此时滚动更新的第一个周期并不会立刻停止而是会等到滚动更新的第一个周期完成后才会处于暂停状态,在下文的滚动更新一节会有例子进行详细的分析,至于 scale 操作在下文也会进行详细分析。
syncDeploymentStatus 方法以及相关的代码在上文的删除操作中已经解释过了,此处不再进行分析。
回滚
kubernetes 中的每一个 Deployment 资源都包含有 revision 这个概念,并且其 .spec.revisionHistoryLimit 字段指定了需要保留的历史版本数,默认为10,每个版本都会对应一个 rs,若发现集群中有大量 0/0 rs 时请不要删除它,这些 rs 对应的都是 deployment 的历史版本,否则会导致无法回滚。当一个 deployment 的历史 rs 数超过指定数时,deployment controller 会自动清理。
当在客户端触发回滚操作时,controller 会调用 getRollbackTo 进行判断并调用 rollback 执行对应的回滚操作。
1 | func (dc *DeploymentController) syncDeployment(key string) error { |
getRollbackTo 通过判断 deployment 是否存在 rollback 对应的注解然后获取其值作为目标版本。
1 | func getRollbackTo(d *apps.Deployment) *extensions.RollbackConfig { |
rollback 方法的主要逻辑如下:
- 1、获取 newRS 和 oldRSs;
- 2、调用
getRollbackTo获取 rollback 的 revision; - 3、判断 revision 以及对应的 rs 是否存在,若 revision 为 0,则表示回滚到上一个版本;
- 4、若存在对应的 rs,则调用
rollbackToTemplate方法将rs.Spec.Template赋值给d.Spec.Template,否则放弃回滚操作;
k8s.io/kubernetes/pkg/controller/deployment/rollback.go:321
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36func (dc *DeploymentController) rollback(d *apps.Deployment, rsList []*apps.ReplicaSet) error {
// 1、获取 newRS 和 oldRSs
newRS, allOldRSs, err := dc.getAllReplicaSetsAndSyncRevision(d, rsList, true)
if err != nil {
return err
}
allRSs := append(allOldRSs, newRS)
// 2、调用 getRollbackTo 获取 rollback 的 revision
rollbackTo := getRollbackTo(d)
// 3、判断 revision 以及对应的 rs 是否存在,若 revision 为 0,则表示回滚到最新的版本
if rollbackTo.Revision == 0 {
if rollbackTo.Revision = deploymentutil.LastRevision(allRSs); rollbackTo.Revision == 0 {
// 4、清除回滚标志放弃回滚操作
return dc.updateDeploymentAndClearRollbackTo(d)
}
}
for _, rs := range allRSs {
v, err := deploymentutil.Revision(rs)
if err != nil {
......
}
if v == rollbackTo.Revision {
// 5、调用 rollbackToTemplate 进行回滚操作
performedRollback, err := dc.rollbackToTemplate(d, rs)
if performedRollback && err == nil {
......
}
return err
}
}
return dc.updateDeploymentAndClearRollbackTo(d)
}
rollbackToTemplate 会判断 deployment.Spec.Template 和 rs.Spec.Template 是否相等,若相等则无需回滚,否则使用 rs.Spec.Template 替换 deployment.Spec.Template,然后更新 deployment 的 spec 并清除回滚标志。
k8s.io/kubernetes/pkg/controller/deployment/rollback.go:751
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17func (dc *DeploymentController) rollbackToTemplate(d *apps.Deployment, rs *apps.ReplicaSet) (bool, error) {
performedRollback := false
// 1、比较 d.Spec.Template 和 rs.Spec.Template 是否相等
if !deploymentutil.EqualIgnoreHash(&d.Spec.Template, &rs.Spec.Template) {
// 2、替换 d.Spec.Template
deploymentutil.SetFromReplicaSetTemplate(d, rs.Spec.Template)
// 3、设置 annotation
deploymentutil.SetDeploymentAnnotationsTo(d, rs)
performedRollback = true
} else {
dc.emitRollbackWarningEvent(d, deploymentutil.RollbackTemplateUnchanged, eventMsg)
}
// 4、更新 deployment 并清除回滚标志
return performedRollback, dc.updateDeploymentAndClearRollbackTo(d)
}
回滚操作其实就是通过 revision 找到对应的 rs,然后使用 rs.Spec.Template 替换 deployment.Spec.Template 最后驱动 replicaSet 和 pod 达到期望状态即完成了回滚操作,在最新版中,这种使用注解方式指定回滚版本的方法即将被废弃。
扩缩容
当执行 scale 操作时,首先会通过 isScalingEvent 方法判断是否为扩缩容操作,然后通过 dc.sync 方法来执行实际的扩缩容动作。
1 | func (dc *DeploymentController) syncDeployment(key string) error { |
isScalingEvent 的主要逻辑如下所示:
- 1、获取所有的 rs;
- 2、过滤出 activeRS,rs.Spec.Replicas > 0 的为 activeRS;
- 3、判断 rs 的 desired 值是否等于 deployment.Spec.Replicas,若不等于则需要为 rs 进行 scale 操作;
k8s.io/kubernetes/pkg/controller/deployment/sync.go:5261
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22func (dc *DeploymentController) isScalingEvent(......) (bool, error) {
// 1、获取所有 rs
newRS, oldRSs, err := dc.getAllReplicaSetsAndSyncRevision(d, rsList, false)
if err != nil {
return false, err
}
allRSs := append(oldRSs, newRS)
// 2、过滤出 activeRS 并进行比较
for _, rs := range controller.FilterActiveReplicaSets(allRSs) {
// 3、获取 rs annotation 中 deployment.kubernetes.io/desired-replicas 的值
desired, ok := deploymentutil.GetDesiredReplicasAnnotation(rs)
if !ok {
continue
}
// 4、判断是否需要 scale 操作
if desired != *(d.Spec.Replicas) {
return true, nil
}
}
return false, nil
}
在通过 isScalingEvent 判断为 scale 操作时会调用 sync 方法执行,主要逻辑如下:
- 1、获取 newRS 和 oldRSs;
- 2、调用
scale方法进行扩缩容操作; - 3、同步 deployment 的状态;
1 | func (dc *DeploymentController) sync(d *apps.Deployment, rsList []*apps.ReplicaSet) error { |
sync 方法中会调用 scale 方法执行扩容操作,其主要逻辑为:
- 1、通过
FindActiveOrLatest获取 activeRS 或者最新的 rs,此时若只有一个 rs 说明本次操作仅为 scale 操作,则调用scaleReplicaSetAndRecordEvent对 rs 进行 scale 操作,否则此时存在多个 activeRS; - 2、判断 newRS 是否已达到期望副本数,若达到则将所有的 oldRS 缩容到 0;
- 3、若 newRS 还未达到期望副本数,且存在多个 activeRS,说明此时的操作有可能是升级与扩缩容操作同时进行,若 deployment 的更新操作为 RollingUpdate 那么 scale 操作也需要按比例进行:
- 通过
FilterActiveReplicaSets获取所有活跃的 ReplicaSet 对象; - 调用
GetReplicaCountForReplicaSets计算当前 Deployment 对应 ReplicaSet 持有的全部 Pod 副本个数; - 计算 Deployment 允许创建的最大 Pod 数量;
- 判断是扩容还是缩容并对 allRSs 按时间戳进行正向或者反向排序;
- 计算每个 rs 需要增加或者删除的副本数;
- 更新 rs 对象;
- 通过
- 4、若为 recreat 则需要等待更新完成后再进行 scale 操作;
k8s.io/kubernetes/pkg/controller/deployment/sync.go:2941
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92func (dc *DeploymentController) scale(......) error {
// 1、在滚动更新过程中 第一个 rs 的 replicas 数量= maxSuger + dep.spec.Replicas ,
// 更新完成后 pod 数量会多出 maxSurge 个,此处若检测到则应缩减回去
if activeOrLatest := deploymentutil.FindActiveOrLatest(newRS, oldRSs); activeOrLatest != nil {
if *(activeOrLatest.Spec.Replicas) == *(deployment.Spec.Replicas) {
return nil
}
// 2、只更新 rs annotation 以及为 deployment 设置 events
_, _, err := dc.scaleReplicaSetAndRecordEvent(activeOrLatest, *(deployment.Spec.Replicas), deployment)
return err
}
// 3、当调用 IsSaturated 方法发现当前的 Deployment 对应的副本数量已经达到期望状态时就
// 将所有历史版本 rs 持有的副本缩容为 0
if deploymentutil.IsSaturated(deployment, newRS) {
for _, old := range controller.FilterActiveReplicaSets(oldRSs) {
if _, _, err := dc.scaleReplicaSetAndRecordEvent(old, 0, deployment); err != nil {
return err
}
}
return nil
}
// 4、此时说明 当前的 rs 副本并没有达到期望状态并且存在多个活跃的 rs 对象,
// 若 deployment 的更新策略为滚动更新,需要按照比例分别对各个活跃的 rs 进行扩容或者缩容
if deploymentutil.IsRollingUpdate(deployment) {
allRSs := controller.FilterActiveReplicaSets(append(oldRSs, newRS))
allRSsReplicas := deploymentutil.GetReplicaCountForReplicaSets(allRSs)
allowedSize := int32(0)
// 5、计算最大可以创建出的 pod 数
if *(deployment.Spec.Replicas) > 0 {
allowedSize = *(deployment.Spec.Replicas) + deploymentutil.MaxSurge(*deployment)
}
// 6、计算需要扩容的 pod 数
deploymentReplicasToAdd := allowedSize - allRSsReplicas
// 7、如果 deploymentReplicasToAdd > 0,ReplicaSet 将按照从新到旧的顺序依次进行扩容;
// 如果 deploymentReplicasToAdd < 0,ReplicaSet 将按照从旧到新的顺序依次进行缩容;
// 若 > 0,则需要先扩容 newRS,但当在先扩容然后立刻缩容时,若 <0,则需要先删除 oldRS 的 pod
var scalingOperation string
switch {
case deploymentReplicasToAdd > 0:
sort.Sort(controller.ReplicaSetsBySizeNewer(allRSs))
scalingOperation = "up"
case deploymentReplicasToAdd < 0:
sort.Sort(controller.ReplicaSetsBySizeOlder(allRSs))
scalingOperation = "down"
}
deploymentReplicasAdded := int32(0)
nameToSize := make(map[string]int32)
// 8、遍历所有的 rs,计算每个 rs 需要扩容或者缩容到的期望副本数
for i := range allRSs {
rs := allRSs[i]
if deploymentReplicasToAdd != 0 {
// 9、调用 GetProportion 估算出 rs 需要扩容或者缩容的副本数
proportion := deploymentutil.GetProportion(rs, *deployment, deploymentReplicasToAdd, deploymentReplicasAdded)
nameToSize[rs.Name] = *(rs.Spec.Replicas) + proportion
deploymentReplicasAdded += proportion
} else {
nameToSize[rs.Name] = *(rs.Spec.Replicas)
}
}
// 10、遍历所有的 rs,第一个最活跃的 rs.Spec.Replicas 加上上面循环中计算出
// 其他 rs 要加或者减的副本数,然后更新所有 rs 的 rs.Spec.Replicas
for i := range allRSs {
rs := allRSs[i]
// 11、要扩容或者要删除的 rs 已经达到了期望状态
if i == 0 && deploymentReplicasToAdd != 0 {
leftover := deploymentReplicasToAdd - deploymentReplicasAdded
nameToSize[rs.Name] = nameToSize[rs.Name] + leftover
if nameToSize[rs.Name] < 0 {
nameToSize[rs.Name] = 0
}
}
// 12、对 rs 进行 scale 操作
if _, _, err := dc.scaleReplicaSet(rs, nameToSize[rs.Name], deployment, scalingOperation); err != nil {
return err
}
}
}
return nil
}
上述方法中有一个重要的操作就是在第 9 步调用 GetProportion 方法估算出 rs 需要扩容或者缩容的副本数,该方法中计算副本数的逻辑如下所示:
k8s.io/kubernetes/pkg/controller/deployment/util/deployment_util.go:4661
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32func GetProportion(rs *apps.ReplicaSet, d apps.Deployment, deploymentReplicasToAdd, deploymentReplicasAdded int32) int32 {
if rs == nil || *(rs.Spec.Replicas) == 0 || deploymentReplicasToAdd == 0 || deploymentReplicasToAdd == deploymentReplicasAdded {
return int32(0)
}
// 调用 getReplicaSetFraction 方法
rsFraction := getReplicaSetFraction(*rs, d)
allowed := deploymentReplicasToAdd - deploymentReplicasAdded
if deploymentReplicasToAdd > 0 {
return integer.Int32Min(rsFraction, allowed)
}
return integer.Int32Max(rsFraction, allowed)
}
func getReplicaSetFraction(rs apps.ReplicaSet, d apps.Deployment) int32 {
if *(d.Spec.Replicas) == int32(0) {
return -*(rs.Spec.Replicas)
}
deploymentReplicas := *(d.Spec.Replicas) + MaxSurge(d)
annotatedReplicas, ok := getMaxReplicasAnnotation(&rs)
if !ok {
annotatedReplicas = d.Status.Replicas
}
// 计算 newRSSize 的公式
newRSsize := (float64(*(rs.Spec.Replicas) * deploymentReplicas)) / float64(annotatedReplicas)
// 返回最终计算出的结果
return integer.RoundToInt32(newRSsize) - *(rs.Spec.Replicas)
}
滚动更新
deployment 的更新方式有两种,其中滚动更新是最常用的,下面就看看其具体的实现。
1 | func (dc *DeploymentController) syncDeployment(key string) error { |
通过判断 d.Spec.Strategy.Type ,当更新操作为 rolloutRolling 时,会调用 rolloutRolling 方法进行操作,具体的逻辑如下所示:
- 1、调用
getAllReplicaSetsAndSyncRevision获取所有的 rs,若没有 newRS 则创建; - 2、调用
reconcileNewReplicaSet判断是否需要对 newRS 进行 scaleUp 操作; - 3、如果需要 scaleUp,更新 Deployment 的 status,添加相关的 condition,直接返回;
- 4、调用
reconcileOldReplicaSets判断是否需要为 oldRS 进行 scaleDown 操作; - 5、如果两者都不是则滚动升级很可能已经完成,此时需要检查 deployment status 是否已经达到期望状态,并且根据
deployment.Spec.RevisionHistoryLimit的值清理 oldRSs;
1 | func (dc *DeploymentController) rolloutRolling(......) error { |
reconcileNewReplicaSet 主要逻辑如下:
- 1、判断
newRS.Spec.Replicas和deployment.Spec.Replicas是否相等,如果相等则直接返回,说明已经达到期望状态; - 2、若
newRS.Spec.Replicas>deployment.Spec.Replicas,则说明 newRS 副本数已经超过期望值,调用dc.scaleReplicaSetAndRecordEvent进行 scale down; - 3、此时
newRS.Spec.Replicas<deployment.Spec.Replicas,调用NewRSNewReplicas为 newRS 计算所需要的副本数,计算原则遵守maxSurge和maxUnavailable的约束; - 4、调用
scaleReplicaSetAndRecordEvent更新 newRS 对象,设置
rs.Spec.Replicas、rs.Annotations[DesiredReplicasAnnotation] 以及 rs.Annotations[MaxReplicasAnnotation] ;
k8s.io/kubernetes/pkg/controller/deployment/rolling.go:691
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22func (dc *DeploymentController) reconcileNewReplicaSet(......) (bool, error) {
// 1、判断副本数是否已达到了期望值
if *(newRS.Spec.Replicas) == *(deployment.Spec.Replicas) {
return false, nil
}
// 2、判断是否需要 scale down 操作
if *(newRS.Spec.Replicas) > *(deployment.Spec.Replicas) {
scaled, _, err := dc.scaleReplicaSetAndRecordEvent(newRS, *(deployment.Spec.Replicas), deployment)
return scaled, err
}
// 3、计算 newRS 所需要的副本数
newReplicasCount, err := deploymentutil.NewRSNewReplicas(deployment, allRSs, newRS)
if err != nil {
return false, err
}
// 4、如果需要 scale ,则更新 rs 的 annotation 以及 rs.Spec.Replicas
scaled, _, err := dc.scaleReplicaSetAndRecordEvent(newRS, newReplicasCount, deployment)
return scaled, err
}
NewRSNewReplicas 是为 newRS 计算所需要的副本数,该方法主要逻辑为:
- 1、判断更新策略;
- 2、计算 maxSurge 值;
- 3、通过 allRSs 计算 currentPodCount 的值;
- 4、最后计算 scaleUpCount 值;
k8s.io/kubernetes/pkg/controller/deployment/util/deployment_util.go:8141
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27func NewRSNewReplicas(......) (int32, error) {
switch deployment.Spec.Strategy.Type {
case apps.RollingUpdateDeploymentStrategyType:
// 1、计算 maxSurge 值
maxSurge, err := intstrutil.GetValueFromIntOrPercent(deployment.Spec.Strategy.RollingUpdate.MaxSurge, int(*(deployment.Spec.Replicas)), true)
if err != nil {
return 0, err
}
// 2、累加 rs.Spec.Replicas 获取 currentPodCount
currentPodCount := GetReplicaCountForReplicaSets(allRSs)
maxTotalPods := *(deployment.Spec.Replicas) + int32(maxSurge)
if currentPodCount >= maxTotalPods {
return *(newRS.Spec.Replicas), nil
}
// 3、计算 scaleUpCount
scaleUpCount := maxTotalPods - currentPodCount
scaleUpCount = int32(integer.IntMin(int(scaleUpCount), int(*(deployment.Spec.Replicas)-*(newRS.Spec.Replicas))))
return *(newRS.Spec.Replicas) + scaleUpCount, nil
case apps.RecreateDeploymentStrategyType:
return *(deployment.Spec.Replicas), nil
default:
return 0, fmt.Errorf("deployment type %v isn't supported", deployment.Spec.Strategy.Type)
}
}
reconcileOldReplicaSets 的主要逻辑如下:
- 1、通过 oldRSs 和 allRSs 获取 oldPodsCount 和 allPodsCount;
- 2、计算 deployment 的 maxUnavailable、minAvailable、newRSUnavailablePodCount、maxScaledDown 值,当 deployment 的 maxSurge 和 maxUnavailable 值为百分数时,计算 maxSurge 向上取整而 maxUnavailable 则向下取整;
- 3、清理异常的 rs;
- 4、计算 oldRS 的 scaleDownCount;
1 | func (dc *DeploymentController) reconcileOldReplicaSets(......) (bool, error) { |
通过上面的代码可以看出,滚动更新过程中主要是通过调用reconcileNewReplicaSet对 newRS 不断扩容,调用 reconcileOldReplicaSets 对 oldRS 不断缩容,最终达到期望状态,并且在整个升级过程中,都严格遵守 maxSurge 和 maxUnavailable 的约束。
不论是在 scale up 或者 scale down 中都是调用 scaleReplicaSetAndRecordEvent 执行,而 scaleReplicaSetAndRecordEvent 又会调用 scaleReplicaSet 来执行,两个操作都是更新 rs 的 annotations 以及 rs.Spec.Replicas。
1 | scale down |
滚动更新示例
上面的代码看起来非常的枯燥,只看源码其实并不能完全理解整个滚动升级的流程,此处举个例子说明一下:
创建一个 nginx-deployment 有10 个副本,等 10 个 pod 都启动完成后如下所示:1
2
3
4
5$ kubectl create -f nginx-dep.yaml
$ kubectl get rs
NAME DESIRED CURRENT READY AGE
nginx-deployment-68b649bd8b 10 10 10 72m
然后更新 nginx-deployment 的镜像,默认使用滚动更新的方式:1
$ kubectl set image deploy/nginx-deployment nginx-deployment=nginx:1.9.3
此时通过源码可知会计算该 deployment 的 maxSurge、maxUnavailable 和 maxAvailable 的值,分别为 3、2 和 13,计算方法如下所示:1
2
3
4
5
6
7// 向上取整为 3
maxSurge = replicas * deployment.spec.strategy.rollingUpdate.maxSurge(25%)= 2.5
// 向下取整为 2
maxUnavailable = replicas * deployment.spec.strategy.rollingUpdate.maxUnavailable(25%)= 2.5
maxAvailable = replicas(10) + MaxSurge(3) = 13
如上面代码所说,更新时首先创建 newRS,然后为其设定 replicas,计算 newRS replicas 值的方法在NewRSNewReplicas 中,此时计算出 replicas 结果为 3,然后更新 deployment 的 annotation,创建 events,本次 syncLoop 完成。等到下一个 syncLoop 时,所有 rs 的 replicas 已经达到最大值 10 + 3 = 13,此时需要 scale down oldRSs 了,scale down 的数量是通过以下公式得到的:1
2
3
4
5
6
7
8
9
10
11// 13 = 10 + 3
allPodsCount := deploymentutil.GetReplicaCountForReplicaSets(allRSs)
// 8 = 10 - 2
minAvailable := *(deployment.Spec.Replicas) - maxUnavailable
// ???
newRSUnavailablePodCount := *(newRS.Spec.Replicas) - newRS.Status.AvailableReplicas
// 13 - 8 - ???
maxScaledDown := allPodsCount - minAvailable - newRSUnavailablePodCount
allPodsCount 是 allRSs 的 replicas 之和此时为 13,minAvailable 为 8 ,newRSUnavailablePodCount 此时不确定,但是值在 [0,3] 中,此时假设 newRS 的三个 pod 还处于 containerCreating 状态,则newRSUnavailablePodCount 为 3,根据以上公式计算所知 maxScaledDown 为 2,则 oldRS 需要 scale down 2 个 pod,其 replicas 需要改为 8,此时该 syncLoop 完成。下一个 syncLoop 时在 scaleUp 处计算得知 scaleUpCount = maxTotalPods - currentPodCount,13-3-8=2, 此时 newRS 需要更新 replicase 增加 2。以此轮询直到 newRS replicas 扩容到 10,oldRSs replicas 缩容至 0。
对于上面的示例,可以使用 kubectl get rs -w 进行观察,以下为输出:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22$ kubectl get rs -w
NAME DESIRED CURRENT READY AGE
nginx-deployment-68b649bd8b 10 0 0 0s
nginx-deployment-68b649bd8b 10 10 0 0s
nginx-deployment-68b649bd8b 10 10 10 13s
nginx-deployment-689bff574f 3 0 0 0s
nginx-deployment-68b649bd8b 8 10 10 14s
nginx-deployment-689bff574f 3 0 0 0s
nginx-deployment-689bff574f 3 3 3 1s
nginx-deployment-689bff574f 5 3 0 0s
nginx-deployment-68b649bd8b 8 8 8 14s
nginx-deployment-689bff574f 5 3 0 0s
nginx-deployment-689bff574f 5 5 0 0s
nginx-deployment-689bff574f 5 5 5 6s
......
重新创建
deployment 的另一种更新策略recreate 就比较简单粗暴了,当更新策略为 Recreate 时,deployment 先将所有旧的 rs 缩容到 0,并等待所有 pod 都删除后,再创建新的 rs。
1 | func (dc *DeploymentController) syncDeployment(key string) error { |
rolloutRecreate 方法主要逻辑为:
- 1、获取 newRS 和 oldRSs;
- 2、缩容 oldRS replicas 至 0;
- 3、创建 newRS;
- 4、扩容 newRS;
- 5、同步 deployment 状态;
1 | func (dc *DeploymentController) rolloutRecreate(......) error { |
判断 deployment 是否存在 newRS 是在 deploymentutil.FindNewReplicaSet 方法中进行判断的,对比 rs.Spec.Template 和 deployment.Spec.Template 中字段的 hash 值是否相等以此进行确定,在上面的几个操作中也多次用到了该方法,此处说明一下。
1 | dc.getAllReplicaSetsAndSyncRevision() --> dc.getNewReplicaSet() --> deploymentutil.FindNewReplicaSet() --> EqualIgnoreHash() |
EqualIgnoreHash 方法如下所示:
k8s.io/kubernetes/pkg/controller/deployment/util/deployment_util.go:6331
2
3
4
5
6
7
8func EqualIgnoreHash(template1, template2 *v1.PodTemplateSpec) bool {
t1Copy := template1.DeepCopy()
t2Copy := template2.DeepCopy()
// Remove hash labels from template.Labels before comparing
delete(t1Copy.Labels, apps.DefaultDeploymentUniqueLabelKey)
delete(t2Copy.Labels, apps.DefaultDeploymentUniqueLabelKey)
return apiequality.Semantic.DeepEqual(t1Copy, t2Copy)
}
以上就是对 deployment recreate 更新策略源码的分析,需要注意的是,该策略会导致服务一段时间不可用,当 oldRS 缩容为 0,newRS 才开始创建,此时无可用的 pod,所以在生产环境中请慎用该更新策略。
总结
本文主要介绍了 deployment 的基本功能以及从源码角度分析其实现,deployment 主要有更新、回滚、扩缩容、暂停与恢复几个主要的功能。从源码中可以看到 deployment 在升级过程中一直会修改 rs 的 replicas 以及 annotation 最终达到最终期望的状态,但是整个过程中并没有体现出 pod 的创建与删除,从开头三者的关系图中可知是 rs 控制 pod 的变化,在下篇文章中会继续介绍 rs 是如何控制 pod 的变化。
参考:
https://my.oschina.net/u/3797264/blog/2966086
https://draveness.me/kubernetes-deployment