iptables 的功能
在前面的文章中已经介绍过 iptable 的一些基本信息,本文会深入介绍 kube-proxy iptables 模式下的工作原理,本文中多处会与 iptables 的知识相关联,若没有 iptables 基础,请先自行补充。
iptables 的功能:
- 流量转发:DNAT 实现 IP 地址和端口的映射;
- 负载均衡:statistic 模块为每个后端设置权重;
- 会话保持:recent 模块设置会话保持时间;
iptables 有五张表和五条链,五条链分别对应为:
- PREROUTING 链:数据包进入路由之前,可以在此处进行 DNAT;
- INPUT 链:一般处理本地进程的数据包,目的地址为本机;
- FORWARD 链:一般处理转发到其他机器或者 network namespace 的数据包;
- OUTPUT 链:原地址为本机,向外发送,一般处理本地进程的输出数据包;
- POSTROUTING 链:发送到网卡之前,可以在此处进行 SNAT;
五张表分别为:
- filter 表:用于控制到达某条链上的数据包是继续放行、直接丢弃(drop)还是拒绝(reject);
- nat 表:network address translation 网络地址转换,用于修改数据包的源地址和目的地址;
- mangle 表:用于修改数据包的 IP 头信息;
- raw 表:iptables 是有状态的,其对数据包有链接追踪机制,连接追踪信息在 /proc/net/nf_conntrack 中可以看到记录,而 raw 是用来去除链接追踪机制的;
- security 表:最不常用的表,用在 SELinux 上;
这五张表是对 iptables 所有规则的逻辑集群且是有顺序的,当数据包到达某一条链时会按表的顺序进行处理,表的优先级为:raw、mangle、nat、filter、security。
iptables 的工作流程如下图所示:
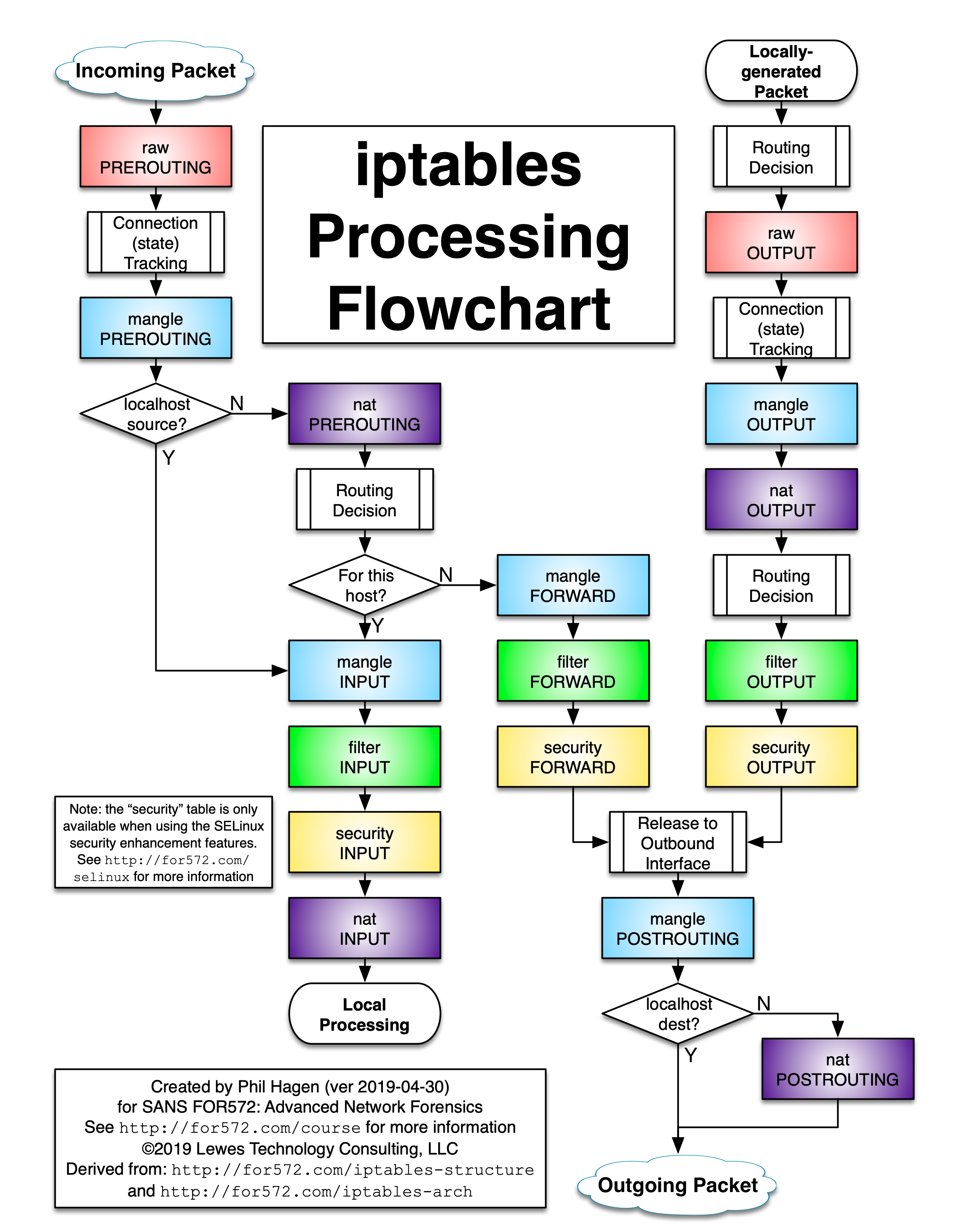
kube-proxy 的 iptables 模式
kube-proxy 组件负责维护 node 节点上的防火墙规则和路由规则,在 iptables 模式下,会根据 service 以及 endpoints 对象的改变来实时刷新规则,kube-proxy 使用了 iptables 的 filter 表和 nat 表,并对 iptables 的链进行了扩充,自定义了 KUBE-SERVICES、KUBE-EXTERNAL-SERVICES、KUBE-NODEPORTS、KUBE-POSTROUTING、KUBE-MARK-MASQ、KUBE-MARK-DROP、KUBE-FORWARD 七条链,另外还新增了以“KUBE-SVC-xxx”和“KUBE-SEP-xxx”开头的数个链,除了创建自定义的链以外还将自定义链插入到已有链的后面以便劫持数据包。
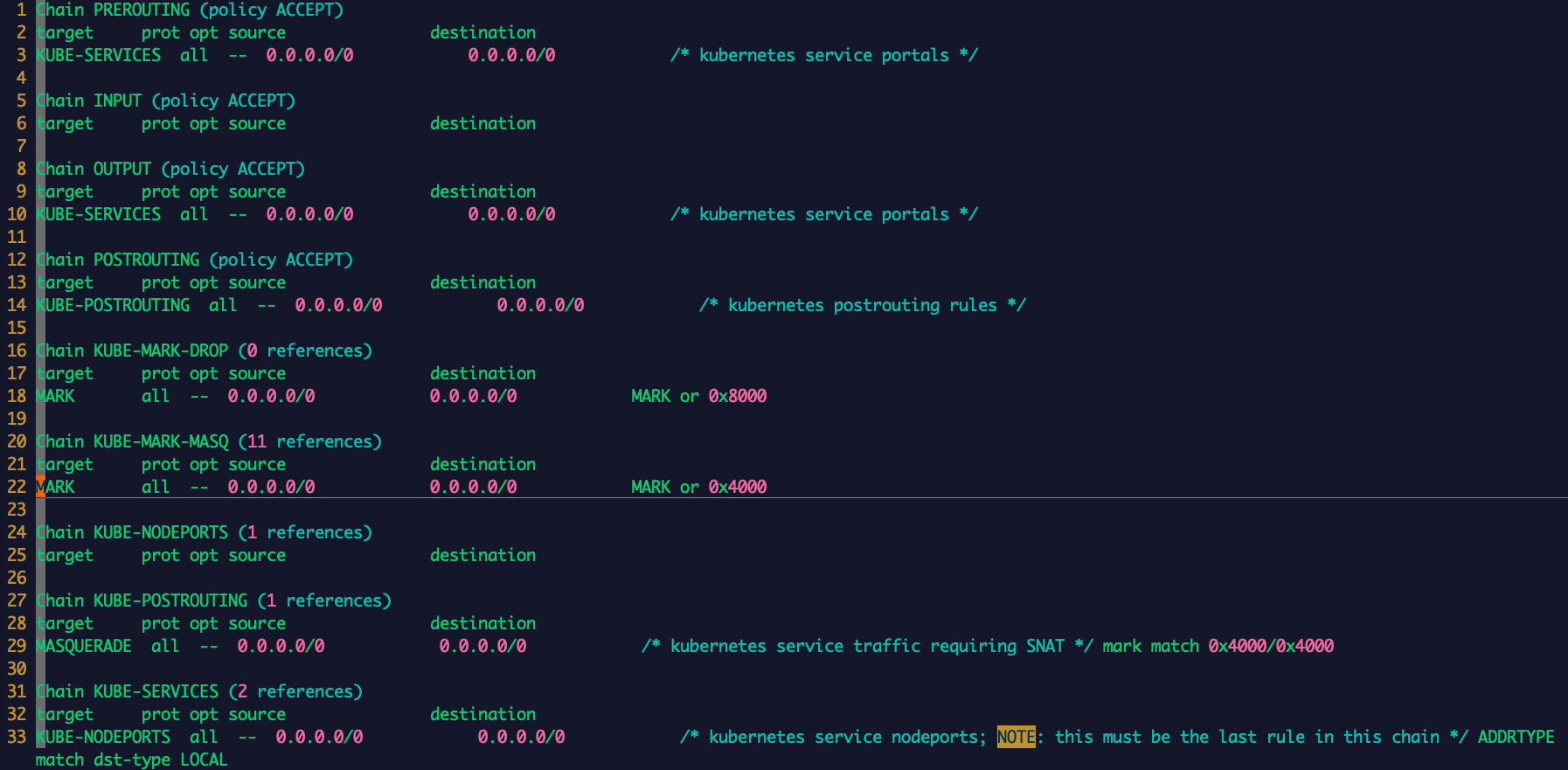
在 nat 表中自定义的链以及追加的链如下所示:
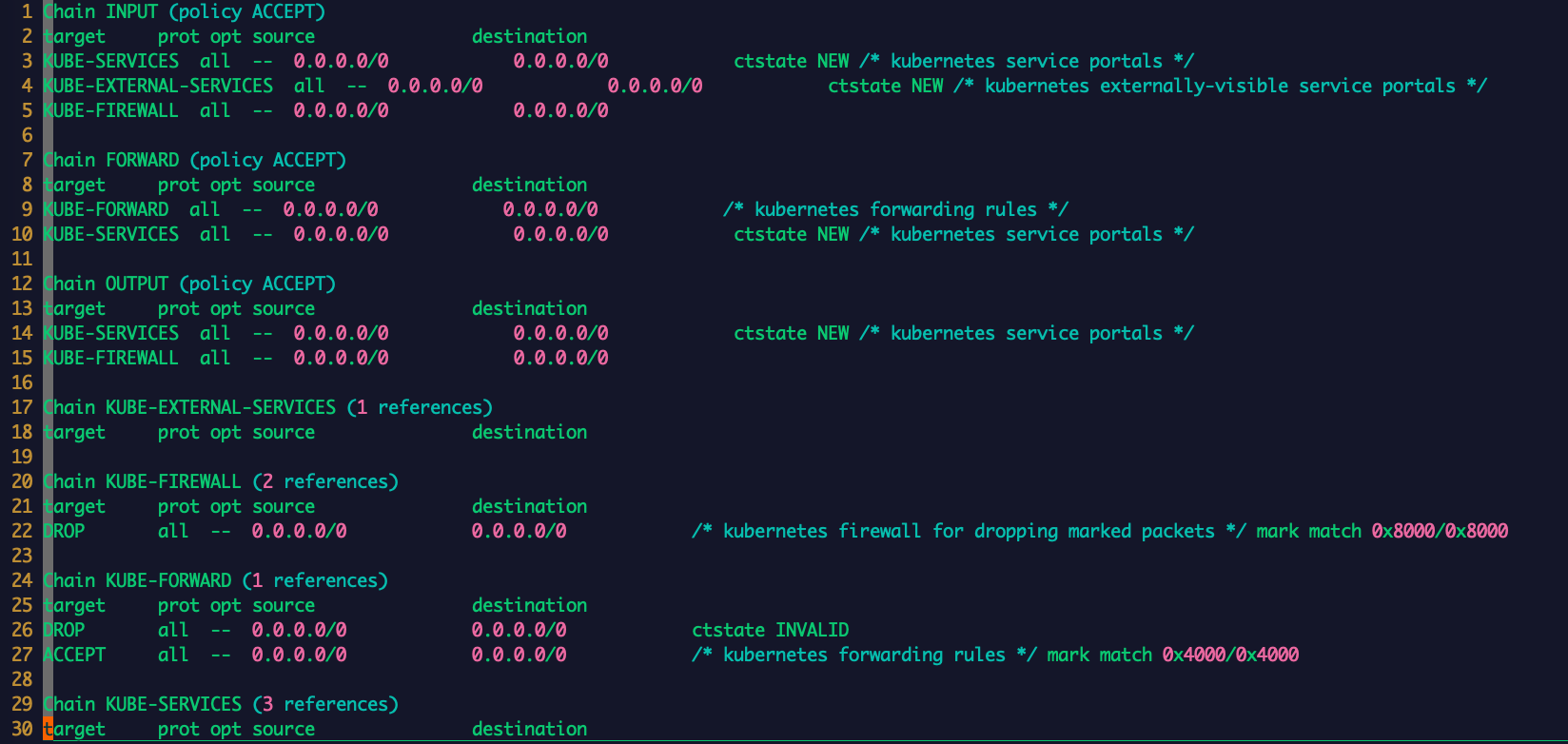
在 filter 表定义的链以及追加的链如下所示如下所示:
对于 KUBE-MARK-MASQ 链中所有规则设置了 kubernetes 独有的 MARK 标记,在 KUBE-POSTROUTING 链中对 node 节点上匹配 kubernetes 独有 MARK 标记的数据包,进行 SNAT 处理。
1 | -A KUBE-MARK-MASQ -j MARK --set-xmark 0x4000/0x4000 |
Kube-proxy 接着为每个服务创建 KUBE-SVC-xxx 链,并在 nat 表中将 KUBE-SERVICES 链中每个目标地址是service 的数据包导入这个 KUBE-SVC-xxx 链,如果 endpoint 尚未创建,则 KUBE-SVC-xxx 链中没有规则,任何 incomming packets 在规则匹配失败后会被 KUBE-MARK-DROP 进行标记然后再 FORWARD 链中丢弃。
这些自定义链与 iptables 的表结合后如下所示,笔者只画出了 PREROUTING 和 OUTPUT 链中追加的链以及部分自定义链,因为 PREROUTING 和 OUTPUT 的首条 NAT 规则都先将所有流量导入KUBE-SERVICE 链中,这样就截获了所有的入流量和出流量,进而可以对 k8s 相关流量进行重定向处理。
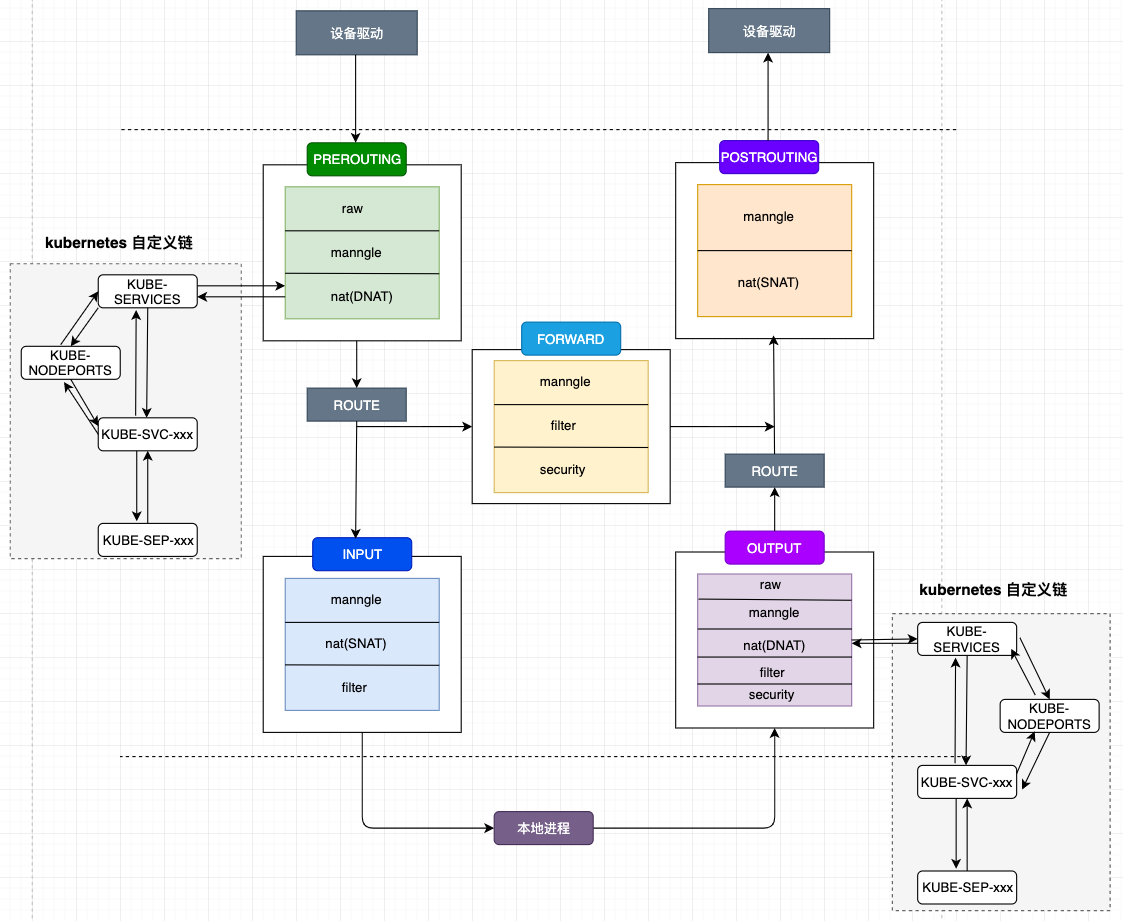
kubernetes 自定义链中数据包的详细流转可以参考:
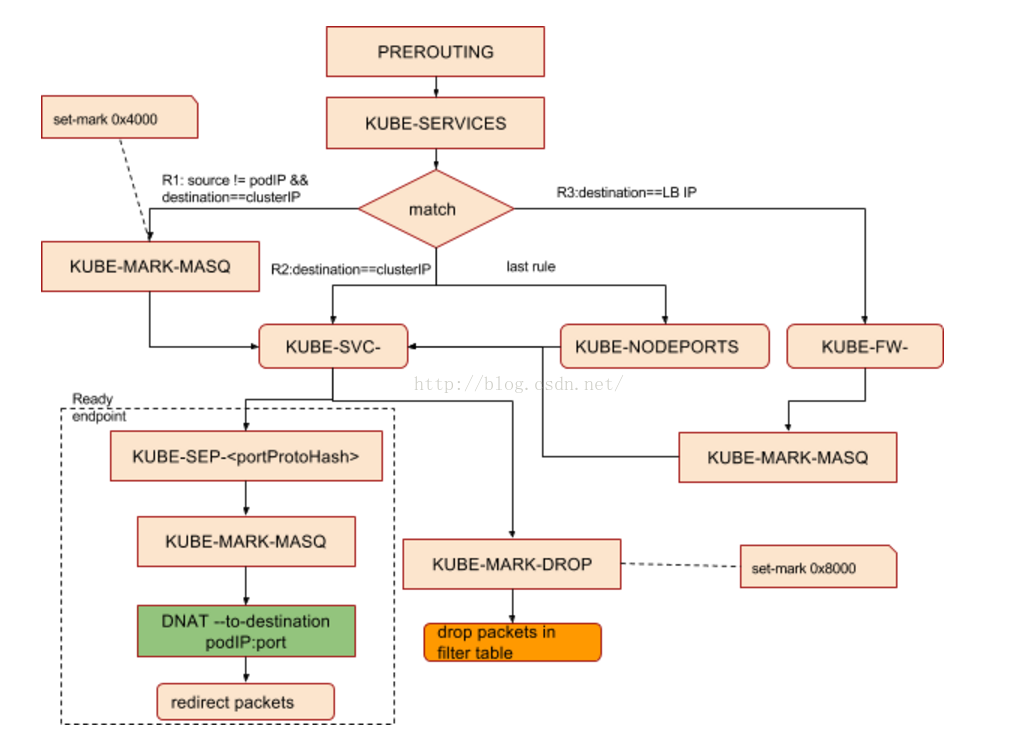
iptables 规则分析
clusterIP 访问方式
创建一个 clusterIP 访问方式的 service 以及带有两个副本,从 pod 中访问 clusterIP 的 iptables 规则流向为:
1 | PREROUTING --> KUBE-SERVICE --> KUBE-SVC-XXX --> KUBE-SEP-XXX |
访问流程如下所示:
- 1、对于进入 PREROUTING 链的都转到 KUBE-SERVICES 链进行处理;
- 2、在 KUBE-SERVICES 链,对于访问 clusterIP 为 10.110.243.155 的转发到 KUBE-SVC-5SB6FTEHND4GTL2W;
- 3、访问 KUBE-SVC-5SB6FTEHND4GTL2W 的使用随机数负载均衡,并转发到 KUBE-SEP-CI5ZO3FTK7KBNRMG 和 KUBE-SEP-OVNLTDWFHTHII4SC 上;
- 4、KUBE-SEP-CI5ZO3FTK7KBNRMG 和 KUBE-SEP-OVNLTDWFHTHII4SC 对应 endpoint 中的 pod 192.168.137.147 和 192.168.98.213,设置 mark 标记,进行 DNAT 并转发到具体的 pod 上,如果某个 service 的 endpoints 中没有 pod,那么针对此 service 的请求将会被 drop 掉;
1 | // 1. |
nodePort 方式
在 nodePort 方式下,会用到 KUBE-NODEPORTS 规则链,通过 iptables -t nat -L -n 可以看到 KUBE-NODEPORTS 位于 KUBE-SERVICE 链的最后一个,iptables 在处理报文时会优先处理目的 IP 为clusterIP 的报文,在前面的 KUBE-SVC-XXX 都匹配失败之后再去使用 nodePort 方式进行匹配。
创建一个 nodePort 访问方式的 service 以及带有两个副本,访问 nodeport 的 iptables 规则流向为:
1、非本机访问
1 | PREROUTING --> KUBE-SERVICE --> KUBE-NODEPORTS --> KUBE-SVC-XXX --> KUBE-SEP-XXX |
2、本机访问
1 | OUTPUT --> KUBE-SERVICE --> KUBE-NODEPORTS --> KUBE-SVC-XXX --> KUBE-SEP-XXX |
该服务的 nodePort 端口为 30070,其 iptables 访问规则和使用 clusterIP 方式访问有点类似,不过 nodePort 方式会比 clusterIP 的方式多走一条链 KUBE-NODEPORTS,其会在 KUBE-NODEPORTS 链设置 mark 标记并转发到 KUBE-SVC-5SB6FTEHND4GTL2W,nodeport 与 clusterIP 访问方式最后都是转发到了 KUBE-SVC-xxx 链。
- 1、经过 PREROUTING 转到 KUBE-SERVICES
- 2、经过 KUBE-SERVICES 转到 KUBE-NODEPORTS
- 3、经过 KUBE-NODEPORTS 转到 KUBE-SVC-5SB6FTEHND4GTL2W
- 4、经过 KUBE-SVC-5SB6FTEHND4GTL2W 转到 KUBE-SEP-CI5ZO3FTK7KBNRMG 和 KUBE-SEP-VR562QDKF524UNPV
- 5、经过 KUBE-SEP-CI5ZO3FTK7KBNRMG 和 KUBE-SEP-VR562QDKF524UNPV 分别转到 192.168.137.147:7000 和 192.168.89.11:7000
1 | // 1. |
其他访问方式对应的 iptables 规则可自行分析。
iptables 模式源码分析
kubernetes 版本:v1.16
上篇文章已经在源码方面做了许多铺垫,下面就直接看 kube-proxy iptables 模式的核心方法。首先回顾一下 iptables 模式的调用流程,kube-proxy 根据给定的 proxyMode 初始化对应的 proxier 后会调用 Proxier.SyncLoop() 执行 proxier 的主循环,而其最终会调用 proxier.syncProxyRules() 刷新 iptables 规则。
1 | proxier.SyncLoop() --> proxier.syncRunner.Loop()-->bfr.tryRun()-->bfr.fn()-->proxier.syncProxyRules() |
proxier.syncProxyRules()这个函数比较长,大约 800 行,其中有许多冗余的代码,代码可读性不佳,我们只需理解其基本流程即可,该函数的主要功能为:
- 更新proxier.endpointsMap,proxier.servieMap
- 创建自定义链
- 将当前内核中 filter 表和 nat 表中的全部规则导入到内存中
- 为每个 service 创建规则
- 为 clusterIP 设置访问规则
- 为 externalIP 设置访问规则
- 为 ingress 设置访问规则
- 为 nodePort 设置访问规则
- 为 endpoint 生成规则链
- 写入 DNAT 规则
- 删除不再使用的服务自定义链
- 使用 iptables-restore 同步规则
首先是更新 proxier.endpointsMap,proxier.servieMap 两个对象。
k8s.io/kubernetes/pkg/proxy/iptables/proxier.go:677
1 | func (proxier *Proxier) syncProxyRules() { |
然后创建所需要的 iptable 链:
1 | for _, jump := range iptablesJumpChains { |
将当前内核中 filter 表和 nat 表中的全部规则临时导出到 buffer 中:
1 | err := proxier.iptables.SaveInto(utiliptables.TableFilter, proxier.existingFilterChainsData) |
检查已经创建出的表是否存在:
1 | for _, chainName := range []utiliptables.Chain{kubeServicesChain, kubeExternalServicesChain, kubeForwardChain} { |
写入 SNAT 地址伪装规则,在 POSTROUTING 阶段对地址进行 MASQUERADE 处理,原始请求源 IP 将被丢失,被请求 pod 的应用看到为 NodeIP 或 CNI 设备 IP(bridge/vxlan设备):
1 | masqRule := []string{ |
为每个 service 创建规则,创建 KUBE-SVC-xxx 和 KUBE-XLB-xxx 链、创建 service portal 规则、为 clusterIP 创建规则:
1 | for svcName, svc := range proxier.serviceMap { |
若服务使用了 externalIP,创建对应的规则:
1 | for _, externalIP := range svcInfo.ExternalIPStrings() { |
若服务使用了 ingress,创建对应的规则:
1 | for _, ingress := range svcInfo.LoadBalancerIPStrings() { |
若使用了 nodePort,创建对应的规则:
1 | if svcInfo.NodePort() != 0 { |
为 endpoint 生成规则链 KUBE-SEP-XXX:
1 | endpoints = endpoints[:0] |
如果创建 service 时指定了 SessionAffinity 为 clientIP 则使用 recent 创建保持会话连接的规则:
1 | if svcInfo.SessionAffinityType() == v1.ServiceAffinityClientIP { |
写入负载均衡和 DNAT 规则,对于 endpoints 中的 pod 使用随机访问负载均衡策略。
- 在 iptables 规则中加入该 service 对应的自定义链“KUBE-SVC-xxx”,如果该服务对应的 endpoints 大于等于2,则添加负载均衡规则;
- 针对非本地 Node 上的 pod,需进行 DNAT,将请求的目标地址设置成候选的 pod 的 IP 后进行路由,KUBE-MARK-MASQ 将重设(伪装)源地址;
1 | for i, endpointChain := range endpointChains { |
若启用了 clusterCIDR 则生成对应的规则链:
1 | if len(proxier.clusterCIDR) > 0 { |
为本机的 pod 开启会话保持:
1 | args = append(args[:0], "-A", string(svcXlbChain)) |
删除不存在服务的自定义链,KUBE-SVC-xxx、KUBE-SEP-xxx、KUBE-FW-xxx、KUBE-XLB-xxx:
1 | for chain := range existingNATChains { |
在 KUBE-SERVICES 链最后添加 nodePort 规则:
1 | addresses, err := utilproxy.GetNodeAddresses(proxier.nodePortAddresses, proxier.networkInterfacer) |
为 INVALID 状态的包添加规则,为 KUBE-FORWARD 链添加对应的规则:
1 | writeLine(proxier.filterRules, |
在结尾添加标志:
1 | writeLine(proxier.filterRules, "COMMIT") |
使用 iptables-restore 同步规则:
1 | proxier.iptablesData.Reset() |
以上就是对 kube-proxy iptables 代理模式核心源码的一个走读。
总结
本文主要讲了 kube-proxy iptables 模式的实现,可以看到其中的 iptables 规则是相当复杂的,在实际环境中尽量根据已有服务再来梳理整个 iptables 规则链就比较清楚了,笔者对于 iptables 的知识也是现学的,文中如有不当之处望指正。上面分析完了整个 iptables 模式的功能,但是 iptable 存在一些性能问题,比如有规则线性匹配时延、规则更新时延、可扩展性差等,为了解决这些问题于是有了 ipvs 模式,在下篇文章中会继续介绍 ipvs 模式的实现。
参考:
https://www.jianshu.com/p/a978af8e5dd8
https://blog.csdn.net/ebay/article/details/52798074
https://blog.csdn.net/horsefoot/article/details/51249161