kubernetes 虽然具有故障自愈和容错能力,但某些组件的异常会导致整个集群不可用,生产环境中将其部署为高可用还是非常有必要的,本文会介绍如何构建一个高可用的 Kubernetes 集群。kuber-controller-manager 和 kube-scheduler 的高可用官方已经实现了,都是通过 etcd 全局锁进行选举实现的,etcd 是一个分布式,强一致的(满足 CAP 的 CP)KV 存储系统,其天然具备高可用。而 apiserver 作为整个系统的核心,所有对数据的修改操作都是通过 apiserver 间接操作 etcd 的,所以 apiserver 的高可用实现是比较关键的。
kube-apiserver 的高可用配置
apiserver 本身是无状态的,可以横向扩展,其借助外部负载均衡软件配置高可用也相对容易,实现方案比较多,但一般会采用外部组件 LVS 或 HAProxy 的方式实现,我们生产环境是通过 LVS 实现的。apiserver 的高可用可以分为集群外高可用和集群内高可用。集群外高可用指对于直接调用 k8s API 的外部用户(例如 kubectl 、kubelet),客户端需要调用 apiserver 的 VIP 以达到高可用,此处 LVS 的部署以及 VIP 的配置不再详细说明。
集群内的高可用配置是指对于部署到集群中的 pod 访问 kubernetes,kubernetes 集群创建完成后默认会启动一个kubernetes的 service 供集群内的 pod 访问,service 的 ClusterIP 默认值为 172.0.0.1 ,每一个 service 对象生成时,都会生成一个用于暴露该对象后端对应 pod 的对象 endpoints,endpoints 中可以看到 apiserver 的实例。访问 kubernetes 的 service,service 会将请求转发到 endpoints 中的 ip 上,此时若 service 中的 endpoints 中没有 IP,则表示 apiserver 无法访问。
1 | $ kubectl get svc kubernetes |
kubernetes v1.9 之前 kube-apiserver service 的高可用也就是 master ip 要加入到 kubernetes service 的 endpoints 中必须要在参数中指定 --apiserver-count 的值,v1.9 出现了另外一个参数 --endpoint-reconciler-type 要取代以前的 --apiserver-count,但是此时该参数默认是禁用的(Alpha 版本),v1.10 也是默认禁用的。v1.11 中 --endpoint-reconciler-type 参数默认开启了,默认值是 lease。--apiserver-count 参数会在 v1.13 中被移除。v1.11 和 v1.12 中还可以使用 --apiserver-count,但前提是需要设置 --endpoint-reconciler-type=master-count。也就是说在 v1.11 以及之后的版本中 apiserver 中不需要进行配置了,启用了几个 apiserver 实例默认都会加到 对应的 endpoints 中。
kube-controller-manager 和 kube-scheduler 的高可用配置
kube-controller-manager 和 kube-scheduler 是由 leader election 实现高可用的,通过向 apiserver 中的 endpoint 加锁的方式来进行 leader election, 启用 leader election 需要在组件的配置中加入以下几个参数:
1 | --leader-elect=true |
组件当前的 leader 会写在 endpoints 的 holderIdentity 字段中, 使用以下命令查看组件当前的 leader:
1 | $ kubectl get endpoints kube-controller-manager --namespace=kube-system -o yaml |
关于 kube-controller-manager 和 kube-scheduler 高可用的实现细节可以参考之前写的一篇文章:kubernets 中组件高可用的实现方式。
etcd 的高可用配置
etcd 是一个分布式集群,也是一个有状态的服务,其天生就是高可用的架构。为了防止 etcd 脑裂,其组成 etcd 集群的个数一般为奇数个(3 或 5 个节点) 。若使用物理机搭建 k8s 集群,理论上集群的规模也会比较大,此时 etcd 也应该使用 3 个或者5 个节点部署一套独立运行的集群。若想要对 etcd 做到自动化运维,可以考虑使用 etcd-operator 将 etcd 集群部署在 k8s 中。
kubernetes 中组件高可用部署的一个架构图:
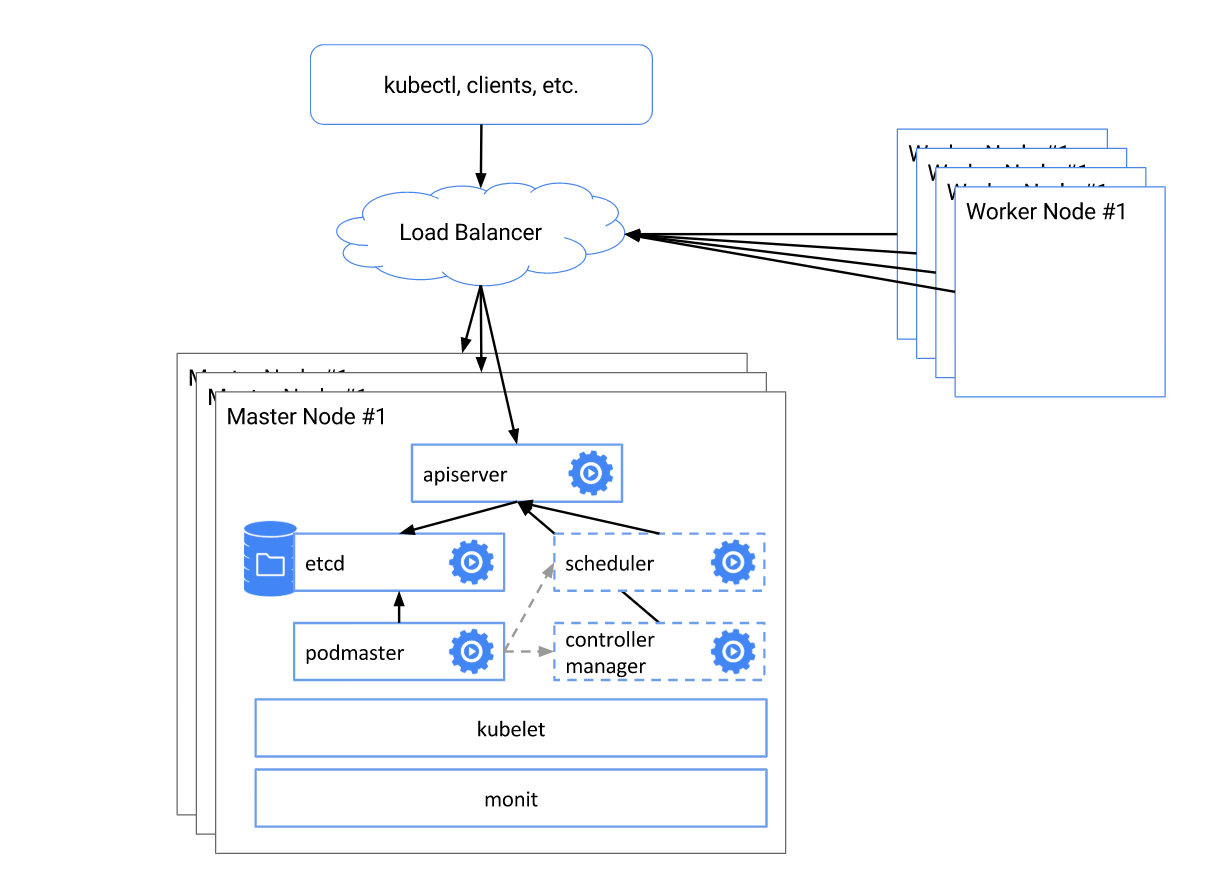
总结
本文主要介绍如何配置一个高可用 kubernetes 集群,kubernetes 新版本已经越来越趋近全面 TLS + RBAC 配置,若 kubernetes 集群还在使用 8080 端口,此时每个 master 节点上的 kube-controller-manager 和 kube-scheduler 都是通过 8080 端口连接 apiserver,若节点上的 apiserver 挂掉,则 kube-controller-manager 和 kube-scheduler 也会随之挂掉。apiserver 作为集群的核心组件,其必须高可用部署,其他组件实现高可用相对容易。
参考: